



03 Jun Distributed Knowledge Representation
 Distributed KR
Distributed KR
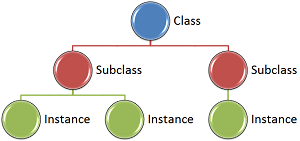
Knowledge representation schemata may be top-down, or bottom-up. In a top-down approach, one would define an area or domain of knowledge, then list the concepts within the domain and their attributes. Behaviors within the domain are often defined by that domain, and the concepts may not be able to exist independently. This approach helps enforce a hierarchy, or taxonomy, and provides the benefits of clean inheritance from broader classes of entities to narrower classes and instances. We discussed this in prior posts. A bottom-up approach may be more distributed in that you start at the concept, describe its attributes, then associate it with a domain, which may be treated as another concept with similar behaviors.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| Intelligent Traveling Salesmen | |
Definitions |
References |
| Tonks 2008 | |
| Michalski 1986 Bobrow 1975 | |
| Valiant 1994 Minsky 1975 |
A semantic network is a concept modeled link structure in which named associations bind concepts together. For example the concept of an apple or a cherry may be associated with a recognizable color, such as red. The concept of a bird may have a heirarchical relationship with a higher order concept in the biological taxonomy with a named association of the form:
Concept: “Bird” Association: “is a(n)” Related Concept: “animal”
A collection of these associated concepts is called a semantic network, a fundamentally distributed knowledge representation model, and may look something like the picture below:

Building semantic networks is a technique for distributing knowledge. Advantages of this type of approach include:
- Robustness
- Object-Oriented Processing Potential
- Expandability
- Process Economy
I will discuss these in greater depth in future posts. Besides all this, distributed models of knowledge storage, access and retrieval are more consistent with information processing in the brain. Processing techniques that can use the knowledge in semantic networks include:
- Logic Programming: good for domains in which problems can be expressed in Horn Clause logic
- Object-Oriented Programming: a good high-level programming technique that is independent of problem domain constraints
- Expert Systems: process rules against a model base that describes patterns of successful outcomes
- Forward-Chaining Inference: can be used for working from the bottom-up to correctly process the input
- Backward-Chaining Inference: knows the patterns of successful outcomes and seeks necessary components in the input
- Business Process Modeling: breaks the problem into sequential process steps that branch based on input and lead to correct outcomes
In addition to semantic networks, there are other knowledge models that serve this domain well:
- OAV or Object-Attribute-Value: good for representing descriptive relations
- Schemata: good for multiple relation types
- Frames, slots and fillers: provide a convenient way to manage parallel processes
These approaches will also be addressed further later.
Domain vs. Process Knowledge
What knowledge must be represented?
| Domain | Knowledge about the things that exist in a domain and their associations |
| Data entities | What are the essential elements of data that must be processed to produce the desired result? |
| Data Relations | What meaningful relations link data elements? What are the characteristics of relations? |
| How do we distinguish causal – hierarchical and descriptive relations? | |
| Process | Knowledge about the steps – functions and rules that affect outcomes in the domain |
| Search | How are data elements distinguished from one another? |
| How do we ensure an element is recognized and not mistaken? | |
| Inference | What is the sequence of decisions that lead to a conclusion and what data and/or relations activate decisions? |
| Do we build a strictly non-deterministic model or do we manipulate graph traversal order or rule firing order? |
Key connections exist between the kinds of knowledge necessary for modeling and the kinds of knowledge necessary for any complex cognitive activity.
Domain knowledge is hierarchical or taxonomical knowledge, while process knowledge is fundamentally causal or active knowledge. The combination of these two is not just essential for designing a good model; both types are essential for any intelligent activity at all.
Seeking Balance
 Choosing a KR scheme should involve a balance of reality and artificiality. If we ignore the nature of the (real) information, the process of (real) problem-solving, or the hardware and software environment of the automation system (artificial), we reduce our potential to deliver a usable system that works. Functionality and usability are separate but equally important in intelligent systems.
Choosing a KR scheme should involve a balance of reality and artificiality. If we ignore the nature of the (real) information, the process of (real) problem-solving, or the hardware and software environment of the automation system (artificial), we reduce our potential to deliver a usable system that works. Functionality and usability are separate but equally important in intelligent systems.
KR has two parts: knowledge and a formalism for representing it. Knowledge is more complex than data or information in that knowledge implies context. The representation formalism must have a set of symbols and a structure that is expressive enough to capture the intricacies of the data, information or knowledge necessary to solve the problem.
Clever artificers are able to manufacture things that are quite useful, deceptively similar imitations of natural things, or both. This is the main thrust of artificial intelligence research and application. One fundamental notion is that the best computer will be the one that performs most like the human brain. Some neural net theories may oversimplify the structure and workings of the brain. This tendency can be overcome by adopting a more balanced approach to neural modeling and other computer simulations.
Selecting a KR Scheme
We now need to build into our model a method for representing the knowledge. Certain questions to answer before selecting a knowledge representation scheme are listed below:
- Does the KR scheme match the problem/knowledge domain?
- Does the KR scheme fill the boundaries?
- Can it represent all knowledge required for problem resolution?
- Is there some domain knowledge the selected scheme cannot represent?
- Does the KR scheme match the reasoning techniques?
- Does the KR scheme match/optimize the hardware platform?
- Does the software/hardware environment suggest optimal representations?
- Does the knowledge acquisition process require a class of KR?
- Will knowledge be compiled for use in the system?
- Does the KR scheme accommodate graceful degradation so the system can break the rules?
Another question we might ask, though it may or may nor apply, is this: “Does the structure resemble the structure of the brain?” We would ask this question when we have chosen brain-like processes and want a structure to support them.
This post is intended to lay a groundwork for evaluating schemes I will discuss in upcoming posts. In particular, please watch for my posts on Big Data in which I will discuss some of the amazing innovations at Google and elsewhere to correlate billions of distributed data elements.
| Click below to look in each Understanding Context section |
|---|
| Intro | Context | 1 | Brains | 2 | Neurons | 3 | Neural Networks |
| 4 | Perception and Cognition | 5 | Fuzzy Logic | 6 | Language and Dialog | 7 | Cybernetic Models |
| 8 | Apps and Processes | 9 | The End of Code | Glossary | Bibliography |
SHARE THIS ARTICLE



