



23 Jun Information Transformation
Information Exchange and Transformation
 Knowledge does the most good when shared. Knowledge that gets lodged in one place may not be particularly useful to many people. But moving digital information from place to place has its dangers. Automating data movement can introduce security or confidentiality issues, data duplication challenges, as well as raising the specter of context collapse. Some corporations and government organizations spend more money on data quality and data compliance issues, mostly associated with information exchange and transformation, than they spend on competitive analytics and improving service quality.
Knowledge does the most good when shared. Knowledge that gets lodged in one place may not be particularly useful to many people. But moving digital information from place to place has its dangers. Automating data movement can introduce security or confidentiality issues, data duplication challenges, as well as raising the specter of context collapse. Some corporations and government organizations spend more money on data quality and data compliance issues, mostly associated with information exchange and transformation, than they spend on competitive analytics and improving service quality.
The evolution from data to information to knowledge makes issues of managing bits and bytes more complex: these digital pathologies will not cure themselves. The rising volume, velocity and variety of data and rich content traversing the information systems portfolio will only compound the problem for organizations. Those that fail to address the need to manage digital information in transit through its transformations will introduce risks to compliance and competitiveness.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| Context is King Indeed | |
Definitions |
References |
| Gear 1969 | |
| Rouse TechTarget | |
| Roshen 2009 |
A key element of this blog is to look at accomplishing automated tasks, both in the context of our ongoing discussion of selecting optimal, and sometimes multiple different techniques to achieve smarter outcomes, and in the broader context of delivering outcomes in a defined value chain or a business. An important means of evaluating any approach is to rate the health and elegance of the interaction.
- Is the interaction simple (making it easier to troubleshoot)?
- Is it compact and quick (reducing the likelihood of collisions, errors and timeouts)?
- Do you achieve the desired outcome?
- For data movement, does the data come through clean?
- Is the data duplicated (often less desirable)?
Another useful way of considering the interaction is to describe the information transformations during each process and the state at each point in the process. Because the junctions are likely to be more stable and describable than many of the internal processes of the modules, this description takes on added importance.

A modular approach is consistent with what we know about brain physiology with its many components that specialize in different cognitive functions. Yet, despite the modularity, the brain, with its relatively slow message travel, is so tightly interconnected that the diverse processes are continually interacting with one another. This works so well in the brain because the characteristics of the processing systems are extremely consistent, never stopping or slowing down, with no bottlenecks, and the results are absolutely consistent. For example, processing in any of the components of the brain yields predictable levels of electrochemical activity in salient loci.
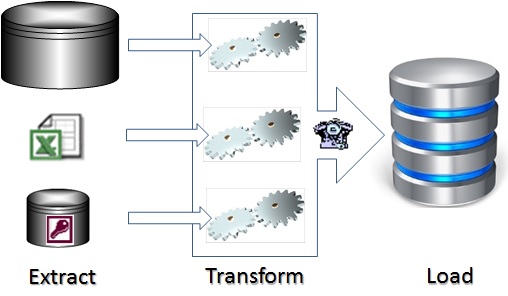 ETL is the common acronym for data movement techniques between digital data sources, representing the processes needed to share or synchronize data between separate databases:
ETL is the common acronym for data movement techniques between digital data sources, representing the processes needed to share or synchronize data between separate databases:
- E: Extract the needed data (hopefully only the needed data) from the source database
- T: Transform the data format as needed while preserving the content/intent
- L: Load the data into the target database
In most cases, the source and target databases have differences in structure, granularity or data types that necessitate transformation before the data is acceptable for loading into the target database. When they are the same, the duplication may be necessitated for performance purposes. For example, transactional databases that need high performance should not be burdened by users performing complex or weighty queries for reporting. In such cases, data is often moved to reporting data stores (RDS) to protect the transactional system from activity that could slow down transactions. It is also common for data, initially acquired through rapid or voluminous transactions, to require further processing through the manual intervention of subject matter experts. In this case, operational data stores (ODS) are called for. Complex analytics often require the data to be structured in cubes or star schemata. All these data movement and synchronization approaches are candidates for automated ETL procedures.
Defining Data Flow Cycles
There are many ways to define the data flow between systems with different costs and benefits. The user requirements will almost always guide software engineers in selecting the best flow cycle. Whether real-time, hourly, nightly, weekly or monthly, and whether the data is synchronized in toto or only that which has changed (the “delta”) depends on whether there is time during the development cycle to do the more elegant delta-based synchronization or the easier to develop, but usually more costly long term total data replacement. The reason it is more costly in the long term is because of the increased bandwidth, temporary storage and processor cycles required to replace everything, especially as the data size grows, as opposed to only replacing data that has changed since the last synch procedure. Sadly, the quarterly SEC reporting cycle and other shortsighted phenomena drive decision makers to cut corners up front and accept years of higher costs as a result.
Canonical Models
A canonical data model is a clear description of the knowledge objects and their associations in the context of the producer and consumer communities that hold a stake in the accuracy and completeness of the subject knowledge. To be effective, the description, definition and eventually, implementation of each knowledge object in the model must be based on agreement of the stakeholders that each object (represented by words or other symbols) about their meanings and the formulas used to derive them. The canonical model may have multiple views, including a taxonomy as shown below, and an object role model in which the interactions between the information elements or categories are articulated in lines that connect the objects.
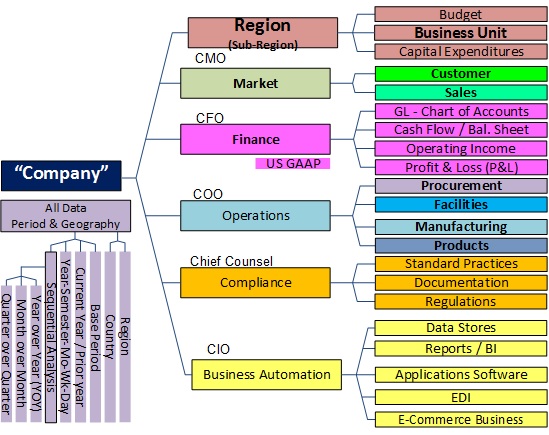
I like to think about processes in the same way. I believe there is a place in systems architecture for canonical process modeling.
At the top level, the place where canonical modeling fits easiest, is the value chain: the process that starts with a consumer need and uses the resources of a business or other organization to deliver services, assemble, manufacture, market, sell and/or deliver products to a customer. The value chains of most organizations remain fairly constant over time, and they serve as the basis for providing automated solutions that help organizations deliver the value, and help consumers find and obtain the products and services they need. The value chain is an arc of individual high level processes strung together to deliver the outcome. Each of the processes in the value chain can be defined at a more detailed level, and these detailed processes often appear in multiple value chains.
At each vertex in the value chain description, there are clusters of data that usually fit into two or three major categories, and as processes move along the value chain, there are inevitably handoffs between detailed processes and different value chains. I will address canonical process modeling in a future post. For today, I have one last thing to say: In the age of knowledge, all data movement and transformation should be overseen, managed and audited by intelligent agents that serve as “keepers of the canonical model”.
| Click below to look in each Understanding Context section |
|---|
SHARE THIS ARTICLE



