



26 Jun The Semantic Web and Model Owls
 Standards protect us and constrain us — not like a straight-jacket protects us from ourselves, but more like a governor on the motor protects us from going crazy. Standards organizations such as the Worldwide Web Consortium (W3C) are there to coordinate between stakeholders to develop a common way of structuring things. The Object Management Group (OMG) is a non-profit, computer industry specifications consortium with membership open to all. Important in-breeding occurs between Source Forge, GitHub and industry in which open source and commercial software, programming language and platform designers collaborate to establish standards that act more like a governor than a straight-jacket. In this blog, I have used the words model and modeling frequently. Today, I’m going to talk about industry standards for semantic modeling (including the “Semantic Web”) and model sharing. — Just for today, please forgive the alphabet soup — Thanks!
Standards protect us and constrain us — not like a straight-jacket protects us from ourselves, but more like a governor on the motor protects us from going crazy. Standards organizations such as the Worldwide Web Consortium (W3C) are there to coordinate between stakeholders to develop a common way of structuring things. The Object Management Group (OMG) is a non-profit, computer industry specifications consortium with membership open to all. Important in-breeding occurs between Source Forge, GitHub and industry in which open source and commercial software, programming language and platform designers collaborate to establish standards that act more like a governor than a straight-jacket. In this blog, I have used the words model and modeling frequently. Today, I’m going to talk about industry standards for semantic modeling (including the “Semantic Web”) and model sharing. — Just for today, please forgive the alphabet soup — Thanks!
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| Do Yawl do Petri Nets | |
Definitions |
References |
Standards W3C OMG |
Sowa 1984 |
| Lenat 1989 CYC | |
| Schank 1986 |
Web Ontology Language (OWL)
 I have briefly mentioned ontology in other posts. The Web Ontology Language is the premier standard for ontological modeling for World Wide Web content. The Semantic Web movement, lead by luminaries such as Roger Schank, John Sowa and Doug Lenat (of CYCorp) have defined a framework for a huge array of technologies based on a solid model of knowledge representation. I am currently doing implementation work for a couple companies using a combination of tools, including BeInformed, that add semantic meaningfulness to business processes, improving outcomes in a way that makes implementation faster and adaptation easier. To me, this is the best of all worlds. I am not going to describe OWL in depth here as W3C provides all the information you need. What I will do is describe the core concept of Triples as a knowledge representation model and briefly describe some of the surrounding technologies.
I have briefly mentioned ontology in other posts. The Web Ontology Language is the premier standard for ontological modeling for World Wide Web content. The Semantic Web movement, lead by luminaries such as Roger Schank, John Sowa and Doug Lenat (of CYCorp) have defined a framework for a huge array of technologies based on a solid model of knowledge representation. I am currently doing implementation work for a couple companies using a combination of tools, including BeInformed, that add semantic meaningfulness to business processes, improving outcomes in a way that makes implementation faster and adaptation easier. To me, this is the best of all worlds. I am not going to describe OWL in depth here as W3C provides all the information you need. What I will do is describe the core concept of Triples as a knowledge representation model and briefly describe some of the surrounding technologies.
In the Beginning…
Back in the day, the great grandfather of markup languages, SGML (Standard Generalized Markup Language – officially recognized by ISO in 1986), itself a descendent of IBM’s ’60s vintage Generalized Markup Language, brought tagging to the forefront of content association. Tagging is the grandfather of what is now often referred to as “Linked Data” and hyperlinked data. Hyperlinking on the Web and in documents enables us to associate and navigate to related documents/pages and specific content within a page or document with the click of a mouse. In the formalism, tags are segregated from regular content using symbols such as <> signs.
The following snippet is from this page showing a level 3 heading: <h3 style=”margin: 0in; color: #333333; font-family: Georgia; font-size: 10.5pt;”>Web Ontology Language (OWL)
In its current understanding, the term Linked Data refers to a set of best practices for publishing and connecting digital content on and off the Web. Some key technologies that support Linked Data are:
- URIs: Uniform Resource Identifier – a symbolic means to identify entities or concepts,
- HTTP: Hypertext Transfer Protocol – a simple mechanism for navigating between content “pages”, and
- RDF: Resource Description Framework – a generic graph-based data model with which to structure and link data that describes things in the world.
These technical capabilities work together to associate symbolic information in meaningful and/or useful ways.
![]()
I will focus on RDF once I lay a bit more foundation.
Objects with Attributes (OAV)
In my post on Data and Modeling, I spoke of the ways in which relational data can be modeled. Besides relational data, there is flat data, multi-dimensional data and other ways of structuring data for storage, use and analysis. The OAV formalism corresponds to data in a table in which the attribute connecting the object and the value is like the column heading in the table. For example, if the object is “basketball” we might see the following OAV triples:
basketball |
shape | spherical |
basketball |
objective | hoop |
basketball |
diameter | 9" |
basketball |
pressure | 7.5# to 8.5# |
The corresponding data table may look like this:
Game |
Ball | Shape | Objective | Diameter | Pressure |
Basketball |
basketball | spherical | hoop | 9" | 7.5# to 8.5# |
Volleyball |
volleyball | spherical | break opponent's volley | 8.5" | 4.5# to 6# |
Softball |
softball | spherical | hit | 3.8" | N/A |
style=”margin: 0in; color: #333333; font-family: Georgia; font-size: 10.5pt;”>This is a data centric model, while RDF and other “Semantic Web” constructs provide mechanisms for binding data across categories in domains to rules and processes that apply to the data.
RDF

Resource Description Framework (RDF) is a standard model for web and organizational data interchange in which the description creates associations. These associations form a graph that is like a Semantic Network (Schank 1986) or a concept graph (Sowa 1984). These graphs are stored in text files using the RDF labels to form a “tagged” data structure. RDF structured data helps with data movement (as discussed in a recent post) and facilitates data merging even if the underlying data structures (schemata) differ, and it elegantly supports schema change, or evolution without requiring changes to all the data connections. 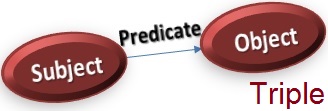 RDF leverages and extends the HTML hyper-linking structure of the World-Wide Web to use URIs to name the relationship between conceptual objects, as well as the two ends of the link. RDF links are usually referred to as “triples”, and they allow structured and semi-structured data to be mixed, exposed, and shared across different systems, platforms and apps.
RDF leverages and extends the HTML hyper-linking structure of the World-Wide Web to use URIs to name the relationship between conceptual objects, as well as the two ends of the link. RDF links are usually referred to as “triples”, and they allow structured and semi-structured data to be mixed, exposed, and shared across different systems, platforms and apps.
This RDF link structure uses directed arrows to describe the functions of the links, forming a directed, labeled graph, in which each named link associates two resources, or graph nodes. This graphical view makes it easier to explain and validate models with knowledge workers who understand the concepts, but are not familiar with modeling. RDFS is RDF Schema: an extension of the basic RDF vocabulary. It provides a data-modeling framework and language for sharing and persistently storing RDF data. Because most organizations use databases for managing data, the ability to get data of all structured types into relational data stores for permanent storage is very important and useful. N-Quads are N-Triples with context. I’ll speak more on this later, but please follow the links I have provided so see how N-Quads offer more context than N-Triples.
MOF
The MetaObject Facility (MOF) Specification is the foundation of OMG’s industry-standard environment where models can be exported from one application, imported into another, transported across a network, stored in a repository and then retrieved, rendered into different formats (including XMI, OMG’s XML-based standard format for model transmission and storage), transformed, and used to generate application code. These functions are not restricted to structural models, or even to models defined in UML – behavioral models and data models also participate in this environment, and non-UML modeling languages can partake also, as long as they are MOF-based.
SKOS
Simple Knowledge Organization System (SKOS) is a set of specifications and standards to support the implementation, use and combining of knowledge assets such as thesauri, classification schemes, subject heading systems and taxonomies within the framework of the Semantic Web. SKOS provides a standard way to represent knowledge organization systems using the RDF. Encoding this information in RDF allows it to be passed between computer applications in an interoperable way. Using RDF also allows knowledge organization systems to be used in distributed, decentralized metadata applications. Decentralized metadata is becoming a typical scenario, where service providers want to add value to metadata harvested from multiple sources.
MDA

I love models. Model Driven Architecture (MDA) is OMG’s architecture standard for model interoperability. Based on MOF-enabled transformations. the MDA unifies every step of the development of an application or integrated suite from its start as a Platform- Independent Model (PIM) of the application’s business functionality and behavior, through one or more Platform-Specific Models (PSMs), to generated code and a deployable application. The PIM remains stable as technology evolves, extending and thereby maximizing software ROI. Portability and interoperability are built into the architecture. MDA relies on the MOF to integrate the modeling steps that start a development or integration project with the coding that follows. You can read about the details on our MDA Specifications Page, which starts by describing the importance of MOF to MDA and continues with references to the additional OMG standards that complete the set. Model portability is so natural that many MDA code generators do not include their own modeling capability – they require users to use their preferred modeler out of a list of compatible candidates.
| Click below to look in each Understanding Context section |
|---|
SHARE THIS ARTICLE



