



07 Jul SPARQL Fireworks
 How do you get at knowledge in conceptually structured information stores such as graphs? There are multiple ways to get data and information in broad use today. The most common is Structured Query Language (SQL) which is used as the almost universal access formalism for getting, storing and manipulating data in relational databases. An emerging standard for getting “Big Data” data is called MapReduce. In honor of US Independence Day, I’d like to take a look at SPARQL, as well as SQL, Cypher, XQuery and MapReduce, and compare their respective models for interacting with data in different structures. I may prepare some future posts to provide greater depth into some of the technologies I mention, as I only brush the surface today.
How do you get at knowledge in conceptually structured information stores such as graphs? There are multiple ways to get data and information in broad use today. The most common is Structured Query Language (SQL) which is used as the almost universal access formalism for getting, storing and manipulating data in relational databases. An emerging standard for getting “Big Data” data is called MapReduce. In honor of US Independence Day, I’d like to take a look at SPARQL, as well as SQL, Cypher, XQuery and MapReduce, and compare their respective models for interacting with data in different structures. I may prepare some future posts to provide greater depth into some of the technologies I mention, as I only brush the surface today.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| Playing the Slots | |
Definitions |
References |
Standards W3C OMG |
ODBMS Article |
| W. Woods in Bobrow 1975 | |
| Neo4j |
We get information from people by asking them, we give it by telling them and we change it by correcting or disabusing them. Using SQL (pronounced like sequel) we get information from databases by “selecting” records, and we give it by “inserting” or “appending” and we change it by “updating”. For example to get Joe’s address we might look into a table called addresses by requesting:
 SELECT Address,City,State,Zip
SELECT Address,City,State,Zip
FROM Addresses
WHERE FirstName = “Joe”
If the database contains more than one address for Joe, we will get more than one record back such as a home address and a work address, thus requiring us to refine the query:
WHERE FirstName = “Joe”
AND AddressType = “Work”
If there are multiple records with the value “Joe” in the FirstName field, we may need to provide a last name as well. If the database has address and name in separate tables, which is quite common when “Joe” may have more than one address (see my post on Data Modeling), you need to look in more than one table, performing a “join” operation. If we can use a “lookup table” to get all the acceptable values for a field, especially during data entry to ensure consistency, this also requires a join using a key. In the normalized model at right, “Gender” is a lookup table. When I first created this table many years ago, there were only two or three broadly recognized genders. This is no longer the case, so the expansion of the model to include other genders does not require changing the logic in the data entry validation routines, just adding the names of the new genders to the table.
The more complex the information you need, the more records that match and the more joins required to get your information, the greater burden is placed on the computing system. Of course, this is true with getting and giving information to humans as well, so this should be no big surprise. The big surprise is, there are ways of speeding things up dramatically.
Beyond Relational Databases – Cypher and XQuery
In the last few posts I have been talking about Semantic Networks and Conceptually Structured knowledge representation models. We’ve long had Object Database Modeling Systems such as Gemstone. Now we’re seeing the growth of Graph Databases, such as Neo4j, that have gained traction as part of the semantic representation “Big Data” movements. Neo4j uses a query language calles Cypher. Cypher is an expressive graph database query language that enables a user or system acting on behalf of a user to ask the database to find data that matches a given pattern. In querying a graph database, you specify the starting point. In Cypher, a SQL select statement may look more like 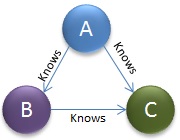 this:
this:
START a=node:user(name=’Michael’)
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c), (a)-[:KNOWS]->(c)
RETURN b, c
In which the starting node (a) is queried for “knows” relationships with nodes (b) and (c). If a match succeeds, the values in nodes (b) and (c) would be in the result set. The establishment of a start node provides a level of control, especially in narrowing the domain context of the query, but the need to specify the start node may be a disadvantage in some cases where you may not know the domain, or when applicable knowledge resides outside the domain.
XQuery is a formalism based on XPath expressions to get and give information stored in XML format, not unlike the way SQL is used for database tables. XQuery is designed to query XML data – not just XML files, but anything that can appear as XML, including all major relational and some graph databases. XQuery is versatile as it can be used to:
- Extract information to use in a Web Service
- Generate summary reports
- Transform XML data to XHTML
- Search Web documents for relevant information
For a good example of XQuery use, look at this tutorial in W3Schools. An example of an XQuery request for data similar to the SQL query above may look like this:
doc(“addresses.xml”)/customers/address[firstname=”Joe”]
For accessing few records with complex information, XML is a great model, as the number of records increases, the performance penalty of parsing the records can become too onerous, mitigating toward a more high-performance solution.
SPARQL for Triples
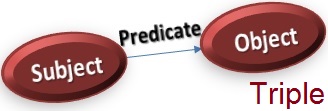 I introduced “subject-predicate-object” triples in my OWL Post. RDF differs from relational data in that the schema is intrinsically part of the data, rather than requiring a schema definition or data dictionary. RDF schema information can be specified in an external ontology to facilitate unambiguous integration of different datasets.
I introduced “subject-predicate-object” triples in my OWL Post. RDF differs from relational data in that the schema is intrinsically part of the data, rather than requiring a schema definition or data dictionary. RDF schema information can be specified in an external ontology to facilitate unambiguous integration of different datasets.
Triples of RDF data can be queried using SPARQL. It is designed to give and get data stored in directed graphs such as Neo4j. SPARQL provides a full set of analytic query operations such as JOIN, SORT, AGGREGATE and provides specific graph traversal syntax for data in a directed graph. An example of SPARQL syntax is:
PREFIX addresses: <http://personsportal.com/addresses/>
SELECT ?name ?address
WHERE {
?person a addresses:Person.
?person addresses:name ?name.
?person addresses:postal ?address.
}
SPARQL Endpoints takes triples or other result data and gives you back data in JSON or other specified formats. The W3C and its coalition of contributors have built a rich set of capabilities for building Semantic Web Applications (SWA) around RDF, OWL and SPARQL, including:
- SPARQL Inferencing Notation (SPIN)
- Semantic Web Rule Language (SWRL)
- SPINMap – maps incoming data to a common domain model
- SPARQLMotion – ETL
- SPARQL Web Pages (SWP)
 Yet another model for storing data is often called “Big Data” and is found in such systems as HBase and Hadoop. It is, in some ways, the opposite structure from Relational databases in that it can be implemented in a single table with no primary or foreign keys. It is a different philosophy from RDF and triples because every record may have a different number of elements, none of which must conform to a subject-predicate-object model, or any other model. I will dive deeper into Big Data in a future post, but for now, I will mention that the most common formalism for getting the data out is called MapReduce.
Yet another model for storing data is often called “Big Data” and is found in such systems as HBase and Hadoop. It is, in some ways, the opposite structure from Relational databases in that it can be implemented in a single table with no primary or foreign keys. It is a different philosophy from RDF and triples because every record may have a different number of elements, none of which must conform to a subject-predicate-object model, or any other model. I will dive deeper into Big Data in a future post, but for now, I will mention that the most common formalism for getting the data out is called MapReduce.
MapReduce is a programming model and an associated implementation for storing and retrieving content in very large data sets. A request is a “map” function that processes a key/value pair to generate a set of intermediate key/value pairs, and a “reduce” function that merges all intermediate values associated with the same intermediate key.
Big Data and MapReduce are not often considered in the same context as SPARQL and RDF. As we look at available options for implementing smart systems, it makes sense for us to acknowledge that MapReduce and SPARQL, though very different in approach, are both used for getting and storing data, and may both be ontology-based.
| Click below to look in each Understanding Context section |
|---|
SHARE THIS ARTICLE



