



14 Apr Knowledge Value-Chain Instrumentation
 The information lifecycle is like a game of telephone – by the time a message gets to the end of the line it is often radically different than it was in the beginning. But this is usually OK because business information is not a game, and there are well-defined processes that bring about each transformation in the chain of custody. For many organizations with complex needs, however, there are gaps created by manual processes or categories of information that don’t abide by the normal rules.
The information lifecycle is like a game of telephone – by the time a message gets to the end of the line it is often radically different than it was in the beginning. But this is usually OK because business information is not a game, and there are well-defined processes that bring about each transformation in the chain of custody. For many organizations with complex needs, however, there are gaps created by manual processes or categories of information that don’t abide by the normal rules.
These gaps, and narrow or missing rules, can impair data quality. When downstream validations, systems or processes turn up errors, it is often necessary to trace information back through multiple paths of lineage to find and fix the problem at its source. Process intelligence and business activity monitoring (BAM) help resolve these issues. Remember this: Bad data originating in your upstream processes will remain bad in your downstream reporting and analytics data stores. The further upstream you can repair and enrich data, the better your reporting and analytics will be. This is where value-chain instrumentation is worth ten times its weight in business benefit.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| Six Reasons Businesses are Implementing Semantics | Stay Tuned |
| Definitions | References |
| BAM semantic meta-knowledge | NISO on Metadata |
| DevOps information process | Davies 2009 Allemang 2011 |
| canonical model rule lineage | Minsky 1968 McCreary 2014 |
Metadata Model
Metadata is data about data, just as meta-knowledge is knowledge about knowledge. The historical lineage of information is often captured in logs for each system in the process flow, but the sequential layout of logs obscures the value-chain for specific information and often forces users to do extensive and time-consuming research to learn where changes occurred. Furthermore, there are many rules in systems, such as workflow systems, spreadsheet macros, or major applications that manipulate and transform data without leaving a trace. Leaving an accessible trace could be a primary role of value-chain instrumentation. The model of storing this information in a database rather than multiple logs, and explicitly associating it with the transactions for a record rather than for a system, dramatically changes the equation, simplifying research, troubleshooting and data quality management.
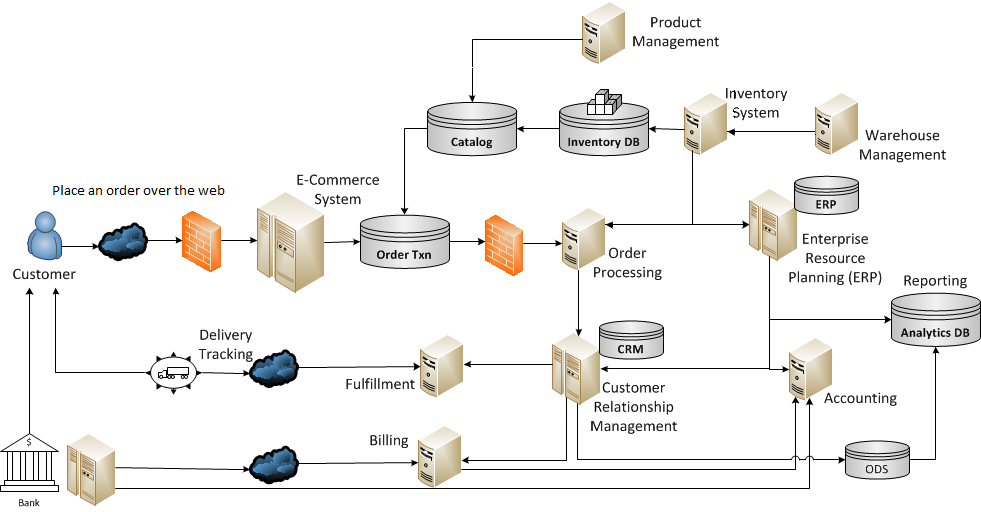
This illustration shows a view of order processing. For some organizations, this may be consistent with their processes, systems and data. For many, this is greatly simplified and hides the many people and processes that process information from the beginning of the chain (a customer looking up a product from a catalog fed by a product management system) to the end of the chain (a business leader analyzing trends in customer feedback to differentiate net promoters from detractors and determine why).
Imagine a situation in which a business executive is trying to learn why there are an unusual number of late delivery complaints from people in a certain city. He understands that, among other possibilities, the problem may be the shipper, the Fulfillment system, delays in processing orders from the Orders system, or inaccurate information in the Inventory system. The more complex a systems portfolio is, and the more data interchange between components in the portfolio, the more value-chain instrumentation is needed. Value-chain instrumentation is a way to make metadata management and master data management more complete and effective because the life of a result can be tracked to its origins.
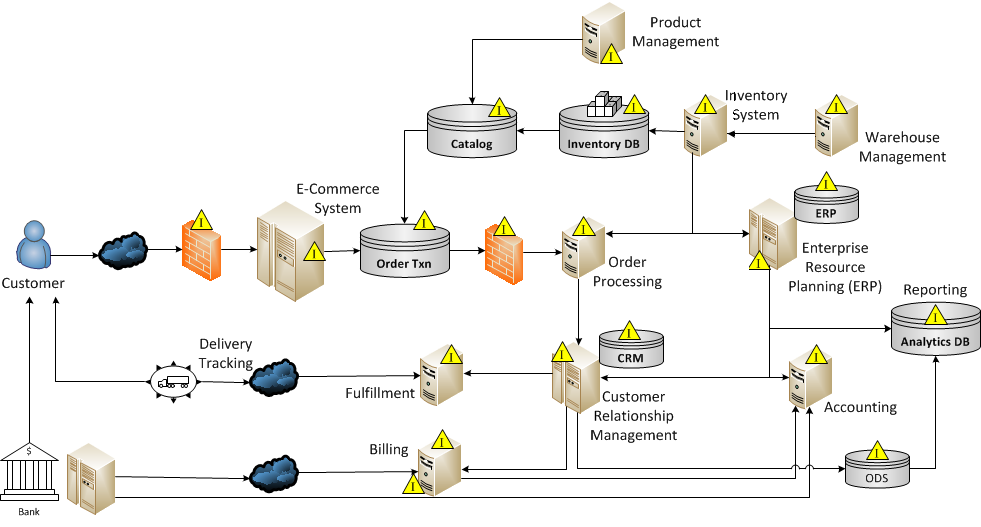
From a systems monitoring perspective, many organizations put sensors throughout the systems infrastructure to track the health of the systems and their connections. Network and systems monitoring and can help preempt failures or quickly restore failed systems and support continuity of operations. Value-chain instrumentation needed to capture lineage and information changes differs from network monitors, but behaves in very similar ways. Places you see a yellow triangle sign in the illustration above represent nodes where instrumentation is needed.
The illustrations above fail to show any people in the loop. Everywhere I’ve ever worked, there are such people, and their contributions are critical to understanding the information value-chain. The instrumentation captures what happened, where and by whom, and sends it on to a place where people can use it to evaluate the success of the process and quality of the data, and perform root cause analyses to troubleshoot and repair problems. In a way, this systematic collaboration mirrors the conceptual foundation of DevOps.
Problem Solving Knowledge
The instrumentation may only flash a colored light or relay the message: “Houston – we have a problem”, so even with advanced instrumentation and some self-healing systems, human intervention and research will be key to the success of this model for the foreseeable future. Not every failure is as problematic as Apollo 13’s venting needed oxygen into space. But the amazing way in which people on the ground and in space collaborated to take the information from the sensors to the instruments, and deliver an outcome that preserved the lives of all the participants, serves as a good example of why instrumentation is necessary.
 How does this relate to “knowledge”? In the human brain, we remember the sequence of events and knowledge that preceded and precipitated any cognitive process. When we don’t know a critical piece of information, we seek it out and add it to the profile of knowledge needed to support our decision processes. The context of any knowledge is its own history. The human process of erecting context is analogous to the process needed to troubleshoot bad data in a complex information ecosystem. Value-chain instrumentation is one of the key elements in erecting context for later reconstructing. It can provide the historical context of a fragment of knowledge, and significantly contribute to the frame of its meaning and the process of resolving its ambiguity.
How does this relate to “knowledge”? In the human brain, we remember the sequence of events and knowledge that preceded and precipitated any cognitive process. When we don’t know a critical piece of information, we seek it out and add it to the profile of knowledge needed to support our decision processes. The context of any knowledge is its own history. The human process of erecting context is analogous to the process needed to troubleshoot bad data in a complex information ecosystem. Value-chain instrumentation is one of the key elements in erecting context for later reconstructing. It can provide the historical context of a fragment of knowledge, and significantly contribute to the frame of its meaning and the process of resolving its ambiguity.
Among the important types of metadata, in an enterprise systems context, are:
- Descriptive metadata describing a category (glossary or ontology) or single instance of a digital resource for discovery and identification with elements such as subject, title, abstract, author, and keywords. This is about definitional meaning, and both canonical models and taxonomical models are descriptive.
- Structural metadata indicates file or data type, formal link structures or how compound objects, such as pages and chapters of a book, are put together.
- Administrative metadata provides information to help manage a resource, such as when,by what system or how itwas created, data lineage, file type and other technical information,and whocan access it. Types of administrative meta-content my include:
- Rights management metadata describing intellectual property rights, and
- Preservation metadata describing policies and procedures governing resource archival and preservation. (NISO on Metadata)
The instrumentation discussed in this post fits into the category of administrative metadata, however, when we discover the people, processes and rules that participated in prior transformations, we start to learn much more about its deep meaning. Metadata or semantic knowledge about content provides insight into what is represented by the tables, columns, attributes, objects, dimensions, files and documents that knowledge workers gather and use to make better  business decisions. The semantic insights include:
business decisions. The semantic insights include:
- Data Element and Category definitions (Descriptive)
- Formulas for combining data into results and performance indicators (Descriptive)
- The nature of associations between related data elements (Structural)
- Source and lineage information , where it came from, what rules were applied and who manipulated it (Administrative)
- The people responsible for managing the metadata (Administrative)
Constructing and managing semantic data can improve both information governance and real-time search and retrieval. Automated mining or electronic metadata discovery can be a great help in building the metadata to begin with and in keeping track of information in day-to-day operations. As this subject is very near and dear to my consulting work, I will bring this subject up periodically, adding what I can each time to develop a more clear picture of not just what it’s about, but how to do it.
| Click below to look in each Understanding Context section |
|---|
| Intro | Context | 1 | Brains | 2 | Neurons | 3 | Neural Networks |
| 4 | Perception and Cognition | 5 | Fuzzy Logic | 6 | Language and Dialog | 7 | Cybernetic Models |
| 8 | Apps and Processes | 9 | The End of Code | Glossary | Bibliography |
SHARE THIS ARTICLE




[…] and redefining automation strategies to improve outcomes. Capabilities to outcomes is the process value chain, which requires coordinating people, process, technology and content. The process model taxonomy is […]