



07 Jun Finding a Tree in the Forest
Complex Search
 Finding the information you need can be a problem, particularly when you have to look through tons (or terabytes) of data. I recall when geocaching first became popular. The idea that a technology could create a model for an entertaining activity that connects people in unusual ways is quite diverting. Will it still be popular when my grandchildren reach their teens? Hard to say. But finding a tree in a forest with the help of a geo-positioning system can actually be fun. The nature of search is evolving.
Finding the information you need can be a problem, particularly when you have to look through tons (or terabytes) of data. I recall when geocaching first became popular. The idea that a technology could create a model for an entertaining activity that connects people in unusual ways is quite diverting. Will it still be popular when my grandchildren reach their teens? Hard to say. But finding a tree in a forest with the help of a geo-positioning system can actually be fun. The nature of search is evolving.
In addition to web search engines and basic file search in your computer, many types of computer applications, such as word processors and database management systems, require search techniques that may be in a menu or an entire language such as Structured Query Language (SQL). These techniques or heuristics may be more or less intelligent. In this post, and a couple more that follow, I’ll review various search techniques and compare their application to the design of intelligent systems.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| In Search of Depth and Breadth | |
Definitions |
References |
| DBMS on WebOPedia | |
| SQL Course at W3Schools | |
| Journal |
It is said that three “V’s” characterize increases in data (and search) challenges in the current waning days of the information age (waning because we are approaching the age of knowledge):
| Growth in | Explanation | Contributors |
| Volume | The amount of data we can consume as individuals and organizations is growing exponentially because the democratization of knowledge has increased the number of people who can author and broadly distribute content | social media; mobile devices; Wi-Fi anywhere; folks like me |
| Variety | Before written language it was words and pictures. Before mass media we added books and newspapers. The information age added radio and television. With internet and the social media revolution we have unlimited amounts of information in many rich formats | Enough bandwidth and storage for video and audio |
| Velocity | The pace of new and newly digitized content available to individuals and organizations makes us multi-task and filter out much of what we could possibly pay attention to. It also requires us to sort things we care about into playlists and folders and picture and video galleries so we can find it later | High speed internet; multi-screen monitors; rapid transit (gets us to information faster) |

Let’s take a couple of minutes to get down to bits and bytes and see why the speed and precision of searching can be so important.
If your data is stored on a tape (a common practice when I first wrote this), and you know where the specific data you need is stored on the tape, you can advance to the place where the data is and start reading. It takes time to advance the tape, and then it takes time to read the data. If you do not know where the data is, but you can tell the computer what to look for, you could start reading the tape from the beginning and search until you recognize the data you’re seeking. This takes more time. Fortunately, we have disk drives that are far faster than tapes, and solid state drives that can be even faster, so searches can be done more quickly. Besides faster hardware, we can also build better and faster search algorithms in software, letting us retrieve the data we need quickly.
Unfortunately, we may not know the best way to formulate our search request: the words we use may not perfectly match the ideas in our minds. This significantly complicates the whole process. Add to that the three Vs, and we have a big problem on our hands.
Search Space
 The objective of searching is to find something, often a string of text, in the filename or in the file contents. Image search in still graphics, photos and video files, and audio search is more complex, but possible with existing technologies. What exactly we’re looking for does not necessarily dictate the search procedures. We may be looking through a list of rules in a rule base, or the list of possible solutions in a solution base, or a list of words in a spell checker. In all these examples, the complete list constitutes the search space.
The objective of searching is to find something, often a string of text, in the filename or in the file contents. Image search in still graphics, photos and video files, and audio search is more complex, but possible with existing technologies. What exactly we’re looking for does not necessarily dictate the search procedures. We may be looking through a list of rules in a rule base, or the list of possible solutions in a solution base, or a list of words in a spell checker. In all these examples, the complete list constitutes the search space.
The search may consist of a simple matching exercise in which we look for a word that is spelled exactly like the word we are checking in our document. This word is called the “goal.” When we make a match, we’re done. We may, however, be searching for a valid solution to a complex problem. In that case, we may actually process each rule in the knowledge-base until we find a solution. This kind of search is not completed until we have solved the problem.
We can describe each word or rule or solution as a node in the network. The collection of all nodes in a network is called the search space. The structure of the search space can influence how we choose to search. This section presents some options for searching through different types of search spaces. Note: The expression “sample space” is sometimes used to mean the same thing as search space. The search space should always be the complete sample space but the opposite is not necessarily true.
The search space is the set of all known answers or solutions.
Forest and Trees
Instead of storing information sequentially, it can be stored in tables or networks such as semantic networks populated with propositions as described in Distributed Knowledge Representation. If it is stored in a table, well-designed indexing schemes and hash functions can facilitate fast and efficient search procedures. Indexing and hash functions are well understood and relatively straightforward, so they are not described further in this post. Data stored in a network, such as a semantic network or multilinked list, is more difficult or impossible to index or hash, so other techniques are needed.

A technique for making a network more searchable is to make it into a tree by storing all possible answers to the questions in the domain into tree-structured network sorted alphabetically or in order of precedence or likelihood. Search can be done by tracing out all possible paths through nodes in the network not yet visited. When we have exhausted nodes or reached a point where all paths lead back to nodes already visited, we’re finished.
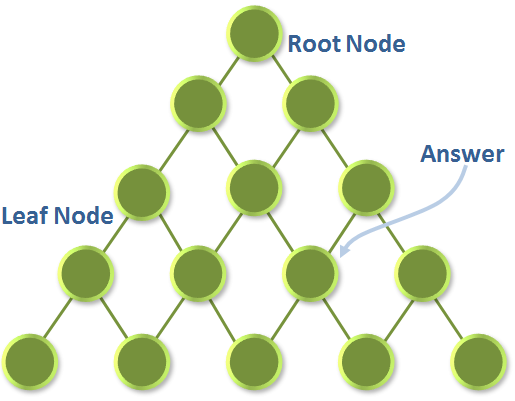 The starting node is the root node, as in genealogical roots. As we go down the inverted tree branches, each new node is a child of the node above it. Nodes on the same level that have the same parent node are called siblings.
The starting node is the root node, as in genealogical roots. As we go down the inverted tree branches, each new node is a child of the node above it. Nodes on the same level that have the same parent node are called siblings.
We are now ready to explore some search procedures for finding data we need in a tree or network.
This illustration shows a tree structure that has a branching factor of two. The maximum number of children is two. Digital logic works fast in twos. No! These little circles are not poker chips! They’re leaves, any one of which may contain the answer for which you’re looking. For simple search with large numbers of similar data elements, this is a great approach. But in a search space where the data is complex, ambiguous, or not amenable to tree structuring, this approach may be less suitable.
Relational Data models don’t use alphabetical or taxonomical organization, but connect related data through primary and foreign keys that associate naturally related data elements. With Object Data models, the organization is more like stream of consciousness, so if you find something similar to what you want, you can search in the proximity of the found data and hope to find something closer to the final answer you seek. With Big Data, you can tag any data element with all the helpful information you choose to make it searchable within the domain, and even across domains. I’ll go into these different strategies more in upcoming posts.
| Click below to look in each Understanding Context section |
|---|
SHARE THIS ARTICLE



