



08 Feb Just In Time Knowledge
 One of the beautiful things about the human brain is it’s adaptability: people can “change” their minds at the last minute based on the changing situation (context). This is not trivial, but I believe that it is one of the characteristics of human cognition that is relatively straightforward to mimic in computer programs and apps. In my experience, the best way to do this is to model the business, the capabilities and the content, in semantically meaningful and digitally usable structured ontologies. Then, based on the models, accumulate all necessary information before deciding the nature of the situation and how best to respond to it.
One of the beautiful things about the human brain is it’s adaptability: people can “change” their minds at the last minute based on the changing situation (context). This is not trivial, but I believe that it is one of the characteristics of human cognition that is relatively straightforward to mimic in computer programs and apps. In my experience, the best way to do this is to model the business, the capabilities and the content, in semantically meaningful and digitally usable structured ontologies. Then, based on the models, accumulate all necessary information before deciding the nature of the situation and how best to respond to it.
This adaptability is indispensable in the face of paradoxical choices, such as whether to save a species from extinction or to save thousands of workers’ jobs, when the options are mutually exclusive. This adaptability is also indispensable when walking down a crowded sidewalk and balancing politeness with a need to hurry. In short, every day, in countless situations, people make adjustments based on new information they received milliseconds ago, and do so successfully most of the time. On the other side of the coin, computer programs tend to be inflexible, treating anything not expected as “garbage” and spitting garbage out. The age of knowledge, and context-based computing should help reduce the flow of garbage.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| Segregating Layers of Intelligence | Inference in Knowledge Apps |
| Definitions | References |
| model context | Sowa 1984 Allemang 2011 |
| meaningful experience | Rummler-Brache Diagrams |
| information ontologies | OMG BPMN Site |
I drew this picture to illustrate how this “just in time knowledge” approach can be reflected in a systems architecture. I’ll talk about “just-in-time” knowledge delivery, then show how this model can make it doable in an enterprise IT ecosystem.
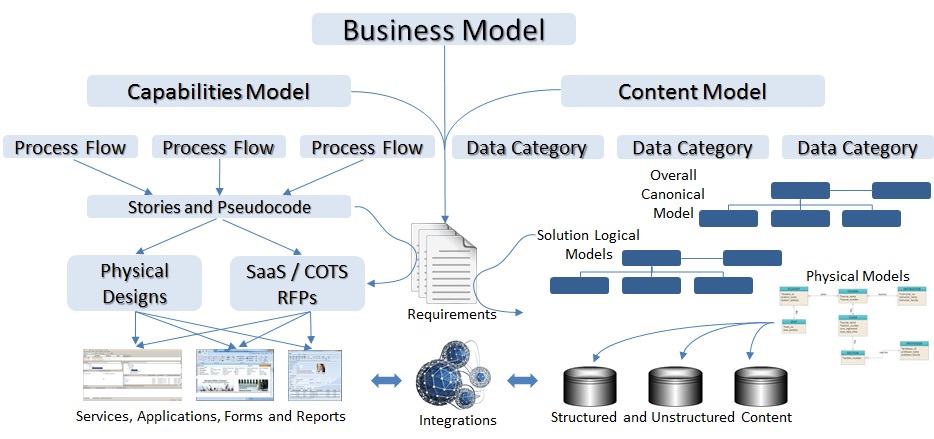
Business Capabilities and Content
A model is a structured representation of the way a business operates, and the information it consumes and generates. Business operations ==> Capabilities Model. Business information ==> Content Model. The content model is often represented as a concept graph (Sowa 1984) or ontology (Allemang 2011) of information categories and their associations; especially functional connections where applicable. Content models often contain hierarchical or parent-child relationships. A content model design may support inheritance in which child objects or concepts inherit the attributes, including applicable processes, or parent concepts or objects. Either ontological and topological model designs may lack support for inheritance, so tools should be selected carefully. Inheritance can be a huge time saver both in up-front development costs and long-term maintenance and enhancement costs, bringing the enterprise closer to the just-in-time knowledge paradigm.
 The process model can be represented using Business Process Model Notation (BPMN – see OMG BPMN Site) as linked, often sequential tasks that may be associated with rules, branching and information requests at specific points in the flow. The specificity of designing points in the flow in which data requests are formulated and initiated may be more important than meets the eye. I’ve seen many “swim lane” models (Rummler-Brache Diagrams) describing the process needed to achieve a specific outcome. In my experience, top level models are needed to ensure that each lower level model is vertically aligned with the organization leadership vision. The sweet spot for knowledge engineers is where the top-down and bottom-up process models meet in the middle.
The process model can be represented using Business Process Model Notation (BPMN – see OMG BPMN Site) as linked, often sequential tasks that may be associated with rules, branching and information requests at specific points in the flow. The specificity of designing points in the flow in which data requests are formulated and initiated may be more important than meets the eye. I’ve seen many “swim lane” models (Rummler-Brache Diagrams) describing the process needed to achieve a specific outcome. In my experience, top level models are needed to ensure that each lower level model is vertically aligned with the organization leadership vision. The sweet spot for knowledge engineers is where the top-down and bottom-up process models meet in the middle.
In traditional applications and screens, you bring up a form or page or screen, and the system requests the needed data based on a set of fixed or user-supplied criteria. In dynamic workflow and model-based solutions, the request is not formulated until a certain point in the flow, and then, only based on the aggregate set of facts ascertained up to that point. Those facts usually come from a combination of user input and proactive system searches. The frequency and quality of these proactive data dips is often a differentiator in the intelligence of a system design. This enables inference rules to be applied, using backward or forward chaining logic to change the criteria and sources queried based on context, and request data that will be most salient to the unique situation. This is part of what I mean by “just in time” knowledge.
 The content model, representing both structured data in tables, and unstructured data in videos, sound files, web pages or documents, can be semantically described with meaningful associations. These associations can bind concepts to each other in hierarchical or other relationships, and can bind processes to specific concepts. This strategy of binding concepts to processes is similar to the way class objects and methods are associated in Object Oriented programming. But in the content models we create, there is no code – only concepts that are bound to other concepts, some of which may point to heuristics, services or programs that can initiate processes and pass them the contextual knowledge needed to provide actionable knowledge when these concepts pop up in an automated business dialog or workflow.
The content model, representing both structured data in tables, and unstructured data in videos, sound files, web pages or documents, can be semantically described with meaningful associations. These associations can bind concepts to each other in hierarchical or other relationships, and can bind processes to specific concepts. This strategy of binding concepts to processes is similar to the way class objects and methods are associated in Object Oriented programming. But in the content models we create, there is no code – only concepts that are bound to other concepts, some of which may point to heuristics, services or programs that can initiate processes and pass them the contextual knowledge needed to provide actionable knowledge when these concepts pop up in an automated business dialog or workflow.
Late (Dynamic) Binding
Static binding is a process associated with compiling code in which functions are placed in line of the sequential code. Compiling involves taking code written in a high-level language such as C# or Java and converting it into machine-level instructions. In the procedural paradigm, early compilers would look for every place in which a procedure is called and place the computer instructions for that procedure right in the middle of the computer instructions for the rest of the program.
In late or dynamic binding, the low-level computer instructions for procedures and functions (or messages) are not placed in line in the sequential low-level computer instructions. Instead, the computer instructions have a built-in table of procedures and functions. Whenever a function call appears in the program, the machine goes to the table, finds the procedure name, goes to the location where the code for the procedure is stored in memory, and executes the code. After the code is executed, control is returned to the main program along with the results of the procedure.
The same principles apply to a service oriented architecture: rather than a massive program with rigid procedures and sequences, build fine- to medium-grained capabilities that are only invoked when needed and terminated when finished. This adds flexibility and conserves computational resources. The services can then be changed independently while everything else is running, and swapped in when ready without changing other systems that use it. Similar principles are changing the way some folks are doing analytics. Many businesses use a common model for Online Analytical Processing (OLAP), in which data is:
- copied into an intermediate or operational data store (ODS) for aggregation, then
- transformed into denormalized structures and
- moved into a data warehouse (DW) where multi-dimensional models such as cubes or star schemata can be assembled, then
- feed data marts (DM) and/or advanced reporting tools where the data can be filtered, sorted and displayed in meaningful ways to help answer questions.
With late binding, the procedures are only incorporated in the sequence of execution when the program needs them at run time.
More and more organizations are seeing huge benefits by moving to an application program interface (API) model and doing away with complex and expensive bulk data synchronization procedures. In this approach it is not necessary to replicate the information into ODSs, DWs and DMs for reporting. Instead, content is queried directly from the sources of record into high-performance “big data” frameworks, which are, by nature, highly denormalized. This advanced APIs model supports improvements in both Transaction Processing (OLTP) and OLAP.
Overloading
Overloading is another valuable, though dangerous addition to the software development lexicon that comes to us courtesy of OOPS. Overloading means giving more than one method the same name, even though the code is different and it is in different objects. Consider the transportation example a few posts back. An aircraft is a form of motorized air transportation. A common procedure for pilots (we hope) is to perform a pre-flight check. To make this method a little more general so it is easily inheritable, we’ll call it a pre-op checklist.
 Before MIPUS takes off on his self-piloting crotch-rocket, he wants to be confident that nothing will go wrong at an inopportune time. Same with his boat and his pickup truck. Whenever he uses any form of transportation, he goes through a pre-op checklist. In this case, the code for the checklist is very simple (see below). The parameters may differ slightly for different objects, and certainly the level of nervousness varies, but the code for the checklist is the same for all of the objects:
Before MIPUS takes off on his self-piloting crotch-rocket, he wants to be confident that nothing will go wrong at an inopportune time. Same with his boat and his pickup truck. Whenever he uses any form of transportation, he goes through a pre-op checklist. In this case, the code for the checklist is very simple (see below). The parameters may differ slightly for different objects, and certainly the level of nervousness varies, but the code for the checklist is the same for all of the objects:
for every item in the checklist of critical items from object
do the check as prescribed in the object’s pre-op method
if results are OK
feel confident about that item
else
feel nervous about that item (even smart robots need cues)
get the troubleshooting methods for the affected item . . .
Securing Dynamic Knowledge Objects
Does an architecture that supports processes that wait until context is constructed before formulating requests introduce security or privacy risks? Unless the privilege model is built into the request process, rather than the overall screen or application instantiation process, this approach can introduce unknowable risks. Consider the meaning of security in a parallel computing environment. Multi-level security on a parallel computer means several things:
- protecting processes
- building walls around clusters of processors
- segregating different security levels in a single cluster
- screening all attempts to access through all front ends
- screening all output to all peripherals
- multi-level encryption for parallel storage resources
Because multiple processes or threads integrating information at one security level can generate information of other security levels, the system must restrict access to users without the proper clearance or without a need-to-know. For just-in-time knowledge from multiple sources, this need-to-know checking should be part of the data request process.
The object-oriented programming paradigm permits explicitly parallel data-driven solutions. We can treat data elements, processes, clearances, clusters, threads, and results of processes as objects. With multiple inheritance assignments, processes and data can be defended in a way commensurate with their sensitivity. In modern programs with late binding, the main program is often smaller than the table of procedures. When we get to the end of code, the only thing that will be left is a table of objects with methods (procedures). The main program may not exist if the device hardware / firmware (or Operating System Kernel) will know how and when to get to the objects.
Of course, the state of the art in operating systems is not close to this level of flexibility, knowledge and power. Apps that come closest to this paradigm, Siri, IBM Watson, Wolfram Alpha…, are still miles away from being able to do these things. But there are glimmers s on the horizon. More to come soon.
| Click below to look in each Understanding Context section |
|---|
| Intro | Context | 1 | Brains | 2 | Neurons | 3 | Neural Networks |
| 4 | Perception and Cognition | 5 | Fuzzy Logic | 6 | Language and Dialog | 7 | Cybernetic Models |
| 8 | Apps and Processes | 9 | The End of Code | Glossary | Bibliography |
SHARE THIS ARTICLE



