



20 Aug Sustainable Software: Three Ways to Future-Proof Enterprise IT
Joe Roushar – August 2016
I have often heard COOs and CIOs lament the fact that systems need to be replaced too frequently because they tend to be brittle and costly to adapt. Yet changes in the marketplace and regulations force companies to update automation capabilities, often requiring rapid change. Mergers and acquisitions compound the problem of unsustainable systems by adding more complexity and opacity to the portfolio of capabilities when the two company’s duplicate capabilities need to be unified.
 Witness the excessive effort and cost around compliance with Sarbanes-Oxley, GLBA, HIPAA and other US laws. ICD-10 and ACA implementation in the healthcare provider and insurance industries cost billions to meet mandates, with little demonstrable business value. Multiply this difficulty by the number of countries and jurisdictions with different mandates, and the complexity grows exponentially. Rapid change in business drivers, industry drivers and technology capabilities all imply the need for changing systems. Agile methodologies and DevOps mentality are probably necessary, but not sufficient. Organizations need stable systems that provide business value day in and day out Paradoxically, where businesses compete, information technology sustainability and adaptability are inextricably linked.
Witness the excessive effort and cost around compliance with Sarbanes-Oxley, GLBA, HIPAA and other US laws. ICD-10 and ACA implementation in the healthcare provider and insurance industries cost billions to meet mandates, with little demonstrable business value. Multiply this difficulty by the number of countries and jurisdictions with different mandates, and the complexity grows exponentially. Rapid change in business drivers, industry drivers and technology capabilities all imply the need for changing systems. Agile methodologies and DevOps mentality are probably necessary, but not sufficient. Organizations need stable systems that provide business value day in and day out Paradoxically, where businesses compete, information technology sustainability and adaptability are inextricably linked.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
The topic of sustainable systems, systems whose characteristics enable them to withstand the tests of time in a world of competitive pressures, is much bigger than can be covered adequately in a few paragraphs. I will concede defeat, and continue to fight on until all my limbs have been hacked off. In fact, much of this blog is about these characteristics, so I will place frequent links throughout this post to related posts and external content that help paint a more complete picture. Here is a summary of the three elements of sustainability in this post:
- Leave your core systems uncustomized and build a highly adaptable intelligent periphery around them
- Formally define taxonomies for both process and content models that define your formula for success
- Implement ML and semantic metadata for integration, security and cognitive search that bind processes and content together
1. Conceptual Process View of Sustainability
I like best the way Steven John (son of Darwin John: CIO excellence in the DNA) articulated the ideal process model for Enterprise Applications and Services. He wanted to be confident that his core applications were stable and would keep delivering business transactions day in and day out, year after year. But he also wanted to be able to adapt systems to meet evolving needs.  His approach was to leave the ERP, CRM, PLM, SFA, and other vendor apps that make up the operational core capabilities, largely untouched. This promotes stability, especially through essential upgrade and patch cycles.
His approach was to leave the ERP, CRM, PLM, SFA, and other vendor apps that make up the operational core capabilities, largely untouched. This promotes stability, especially through essential upgrade and patch cycles.
In this approach, the first element of sustainability, adaptability and evolution occurs at the periphery using intelligent services or microservices, iBPM and PaaS tools, and other components that can be modified quickly without impacting business continuity. This loosely coupled rapid adaptation layer provides the extra intelligence to better empower knowledge workers, and often supports the citizen developer. When non-IT people can redefine processes, the enabling technologies can accelerate productivity and positive outcomes. I will devote another post to the intelligent periphery, but I have addressed some components in my post: Rings of Power: Workflow and Business Rules.
 The data- or content-centric view reflects my personal philosophy that “content is king“, with the proviso that content, handled well, becomes knowledge even before it leaves the computer and enters a human brain. Content includes both structured and unstructured information. The concentric circles in the view below include the same components, but of course, we add the data to the picture in the central content layer. The three layers between core systems and content can be used to build an intelligent periphery.
The data- or content-centric view reflects my personal philosophy that “content is king“, with the proviso that content, handled well, becomes knowledge even before it leaves the computer and enters a human brain. Content includes both structured and unstructured information. The concentric circles in the view below include the same components, but of course, we add the data to the picture in the central content layer. The three layers between core systems and content can be used to build an intelligent periphery.
Remember the combination of security and semantics in the metadata model that wraps itself around the content. In sustainable systems engineering, we ought to combine related information objects that go rightly together instead of many common approaches in which each element is handled by a different system made by a different vendor designed around incompatible standards. To be clear, semantic tags and security related tags that identify sensitivity and access controls are all metadata: the digital content descriptors belong together.
Data access layers have been standard components of enterprise architectures for a couple decades, but they usually include different components for security and privacy related data (roles and privileges) and any other information needed to get the right data (mappings). Making the mappings semantic and putting the access control data in the same metadata is a reasonable and cost effective approach. Loosely coupling the data, and all other content, to the apps and services that use it provides much greater adaptability and flexibility than hard-coding in the connections and queries.
Yet Another Revolution
 Why do we need an intellignet periphery? Consider the difficulties established organizations have adapting to the rise of social apps and mobile devices. New sources of information that may affect a company’s trajectory are popping up everywhere, and most organizations don’t have suitable strategies for acquiring, interpreting and managing the information. Some of this information comes in the form of numbered ratings, but much or most of it may be natural language text with qualitative meaning. Competing in the evolving market requires qualitative, as well as quantitative intelligence. Yet traditional systems are largely limited to indicators derived only from numerical values. The growing speed of business makes this limitation unacceptable.
Why do we need an intellignet periphery? Consider the difficulties established organizations have adapting to the rise of social apps and mobile devices. New sources of information that may affect a company’s trajectory are popping up everywhere, and most organizations don’t have suitable strategies for acquiring, interpreting and managing the information. Some of this information comes in the form of numbered ratings, but much or most of it may be natural language text with qualitative meaning. Competing in the evolving market requires qualitative, as well as quantitative intelligence. Yet traditional systems are largely limited to indicators derived only from numerical values. The growing speed of business makes this limitation unacceptable.
The promise of automation to reduce human labor has yet to catch up to knowledge workers at all levels of the enterprise, leaving it up to workers to gather facts and perform complex analytical work based on little or no “actionable” information. While we want core systems to provide stable transactions and information management functions, we need separate, intelligent capabilities on the periphery to reduce the amount of human analysis needed to extract business value out of information assets.
Unsustainable system challenges
|
2. Define Formal Process and Content Taxonomies
As an enterprise architect, I am focused on IT transformations that begin by understanding capabilities needed to run the business, and redefining automation strategies to improve outcomes. Capabilities to outcomes is the process value chain, which requires coordinating people, process, technology and content. The process model taxonomy is based on a multi-tiered organization of capabilities, functions and processes. This is represented by process flows in the diagram below. The bottom-up view of the organization’s systems portfolio is added by mapping applications and services to the appropriate level (often level 3) in the top down taxonomy.
The content model taxonomy begins with an enterprise canonical information model with domains, categories and concepts. Every database and some documents should map to a category (level 2), and tables and document sections map to concepts (level 3). The number of levels and the names of objects in the taxonomical models are much less important than just doing it. Mapping systems, data and documents into the models at just one point may miss the breadth of process and content within the mapped objects, so a metadata model that permits multiple mapping is even better, though more difficult to maintain.
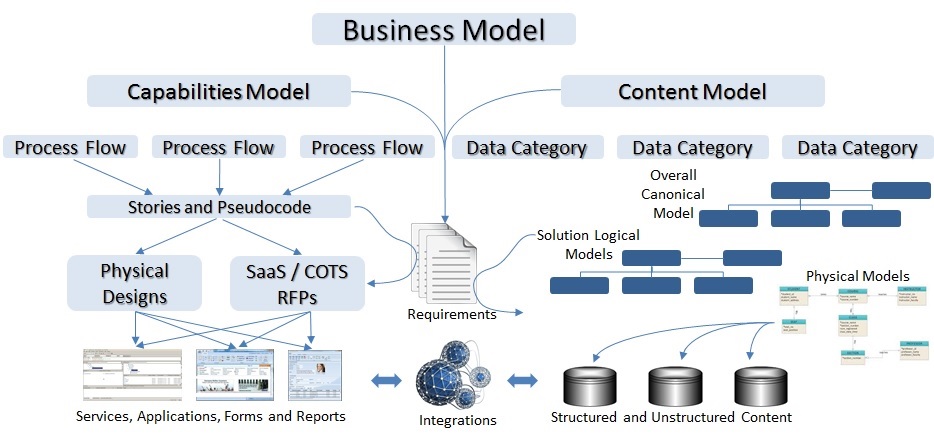
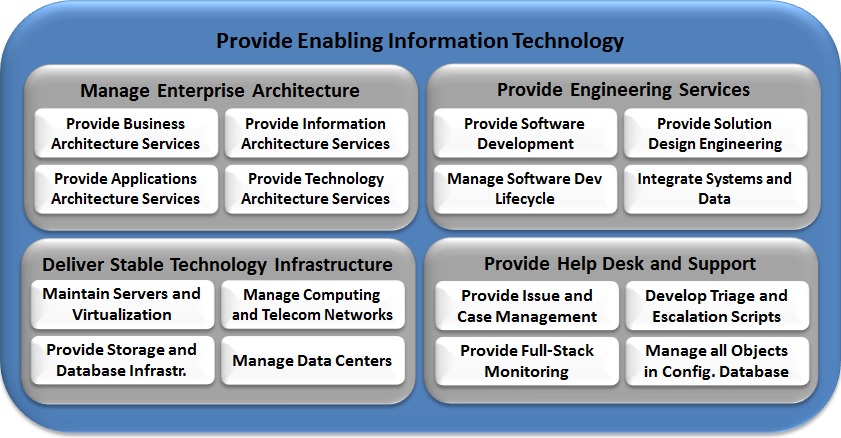
Capabilities models can be started by describing the functional areas controlled from the executive suite ( the Chief x-Team Officers). The top level (L1) capabilities may number fewer than 8 or more than 20, and constitute broad descriptions of business functional areas such as “Manage Finance“, “Administer Human Resources” and “Sell Products“. Inside each of these are more specific groupings of Level 2 or L2 capabilities. For example, in “Provide Enabling Information Technologies” may include “Manage Enterprise Architecture“, “Deliver Stable Technology Infrastructure“, “Provide Engineering Services” and “Provide Help Desk and Support“.
Nesting can be arbitrarily deep, but most approaches I have encountered limit the model to three or four levels at most. Examples of L3 capabilities: within “Deliver Stable Technology Infrastructure” there may be more specific items such as “Maintain servers and virtualization“, “Implement Computing and Telecommunications Networks“, “Provide Storage and Database Infrastructure” and “Manage Data Centers“. Whenever you have an “and” in your capability, there is an opportunity to break it into separate objects, but if the capability is realized using a single person or system, combining them may make sense. Please note that the symmetrical 4×4 model shown below is for example only. Real world models are usually much messier.
I’ll try to remember to show more examples of both process models and content models in future posts. There is a catch to both: you have to keep them up to date. Because both can be significant in breadth, and can be subject to change, it is best to distribute the management responsibility for managing the models among the stakeholders who are most familiar with each functional area of the company. This distribution of metadata management responsibility is often done as part of a data governance board or an architecture governance board, and each stakeholder on the board may be named as a “steward” with specific management scope tied to their area of responsibility in the business.
Explicit Associations: The Glue
Once we have modeled the processes and content that are needed to operate the business and compete, we can formally define the associations between different processes, between concepts and categories, and between the processes and the related concepts. This bottom-up process of placing the processes and concepts in context is the foundation of the semantic enterprise. The big picture of how everything is interconnected may be difficult to understand and even a bit chaotic when viewed as a whole, but labeling links with meaningful associations between nodes creates a context in which the relationships between the processes and content are explicit and consumable. Furthermore, creating and maintaining these linkages in a loosely coupled single ontology, with the help of automated discovery, makes creating it possible and maintaining it manageable.
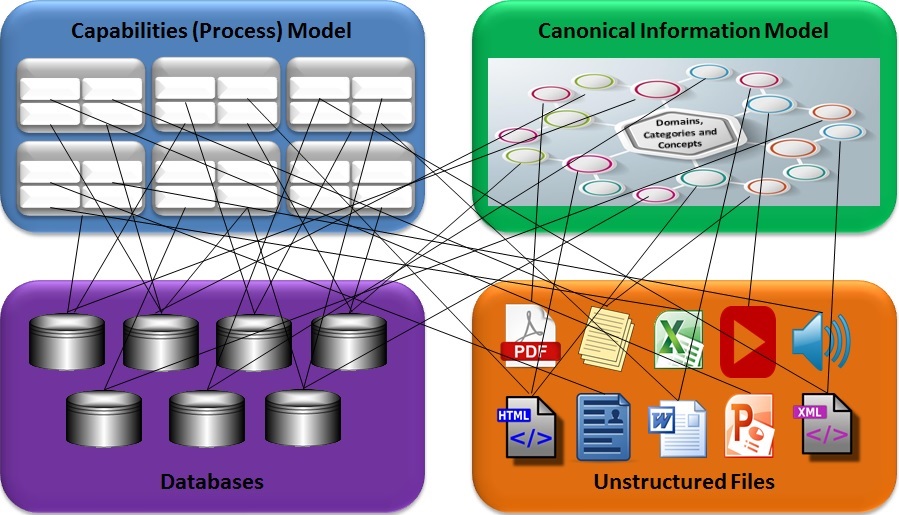
Associations create context that can help users derive insights from multiple disparate systems, and correlate new information, possibly from new external sources (read social media…), with information in the organization’s systems. This can effectively expand an organization’s systems portfolio far beyond the traditional boundaries to include relevant information from external news and social media. For this expansion, to be possible, and to convert externally derived content into valuable assets (qualitative, as well as quantitative) and insights, the intelligent periphery will need to use natural language processing and cognitive computing capabilities to use and create metadata to automatically categorize content in the enterprise content model.
 An important component of my vision for Sustainable Software is that the key to empowering knowledge workers throughout the enterprise is to bind together processes and content in the intelligent periphery with reliable and self-adapting semantic search and query, delivering actionable knowledge. This goes beyond semantic web technologies to business-centric content and process modeling with right-sized machine learning capabilities that assume more intelligent tasks, thus freeing knowledge workers to focus on innovation with a deeper understanding of customers and competitors. I know this is not trivial – please bear with me.
An important component of my vision for Sustainable Software is that the key to empowering knowledge workers throughout the enterprise is to bind together processes and content in the intelligent periphery with reliable and self-adapting semantic search and query, delivering actionable knowledge. This goes beyond semantic web technologies to business-centric content and process modeling with right-sized machine learning capabilities that assume more intelligent tasks, thus freeing knowledge workers to focus on innovation with a deeper understanding of customers and competitors. I know this is not trivial – please bear with me.
Built-in Obsolescence
 As long as information is just traditional data stored as bits and bytes, it is very easy for computers to process, but can be very difficult for humans to understand all its implications. The content is in the machine, but it cannot possibly take on meaning until people read it and use their brains to establish the meaningful connections. It’s not the bits and bytes that are at fault: they are infinitely flexible. Its the traditional data management approach that is limiting. Some of the fundamental differences between most computer software and human information processing, especially the absence of meaningfulness in data, make most software and data obsolete. Augmenting data with semantic metadata, and software with ways of processing it, is the best way to deliver more actionable information requiring less human analysis. My research suggests that both data and metadata about data is in the brain and essential to human cognitive processes.
As long as information is just traditional data stored as bits and bytes, it is very easy for computers to process, but can be very difficult for humans to understand all its implications. The content is in the machine, but it cannot possibly take on meaning until people read it and use their brains to establish the meaningful connections. It’s not the bits and bytes that are at fault: they are infinitely flexible. Its the traditional data management approach that is limiting. Some of the fundamental differences between most computer software and human information processing, especially the absence of meaningfulness in data, make most software and data obsolete. Augmenting data with semantic metadata, and software with ways of processing it, is the best way to deliver more actionable information requiring less human analysis. My research suggests that both data and metadata about data is in the brain and essential to human cognitive processes.
3. Implement Semantic Metadata and ML
Vendors and systems architectures have long envisioned and prototyped semantic capabilities, and semantic layer architectures as part of more agile enterprises. There are tools, including master data management systems, that attempt to achieve many of these benefits. But they require so much manual care and feeding, and contain insufficient semantic context to reduce the amount
of human analysis required to deliver actionable knowledge, or reducing the amount of human analysis needed to make a decision confidently. The gap can be filled with the taxonomical models described in number 2 above, semantic metadata applied at the document and database level, and a machine learning system to build and maintain them.
Machine Learning
 Discovering that knowledge extraction and machine learning capabilities can help workers build and maintain canonical semantic information models, and reliable search and query pre-processors as part of their existing portfolio of systems, will change IT and Business leaders’ perspectives on intelligent systems.
Discovering that knowledge extraction and machine learning capabilities can help workers build and maintain canonical semantic information models, and reliable search and query pre-processors as part of their existing portfolio of systems, will change IT and Business leaders’ perspectives on intelligent systems.
Sustainability in enterprise IT means giving more control to business users over what their systems do for them, without costly, time consuming IT implementation cycles. The best path to this is through cognitive systems, based on enterprise knowledge and process models that span the organization. Continue reading to learn the meaning of sustainable cognitive systems, and the necessity of modeling the full vertical and horizontal ranges of enterprise technologies, as well as the skills and expertise needed to capture the multiple levels of granularity needed to bring cognitive systems to life.
Recent Predictions
In November, 2015 IDC FutureScape predictions included the surprising idea that Cognitive computing would grow from the current 1% of enterprise information systems projects to 50% of projects by 2018. The next week, Jason Bloomberg, in Forbes Magazine, described new tools that are appearing to help companies make this transition. I intend to lay out, in this blog, a set of strategies that will accelerate the digital transformation, while bringing about long-term IT savings.
I see three distinct views of the benefits of sustainability in software engineering:
- Business View (what sustainable software brings businesses)
- Competitive Differentiation
- Adaptability
- Speed to Insight
- IT View (what sustainable software brings businesses)
- Cost and effort of implementing new capabilities
- Cost and effort of supporting operational systems
- Pain-quotient of governed and ungoverned change
- Transformational View (Change is inevitable – sustainability characterizes good change)
- Is the direction of change positive, and how do you know?
- Is the velocity of change sustainable (not to fast or slow)?
- Is the turbulence created by change acceptable, or does it increase firefighting beyond acceptable levels?
 In Semantic Leaps, Seana Coulson, speaking of Neil Armstrong’s “Giant Leap” suggests that “Like interpretation of an action such as stepping onto the moon, interpreting the meaning and significance of natural language utterances depends crucially on contextual factors and background knowledge” (Coulson 2001). Context is often considered to include the time, the location, the topic of discussion and other obvious factors that affect the topic being discussed or described in a document or database. Background knowledge, including exformation and subtext may also be included in context. I assume that systems that are broadly capable of delivering users actionable knowledge will be based on deep understanding of context.
In Semantic Leaps, Seana Coulson, speaking of Neil Armstrong’s “Giant Leap” suggests that “Like interpretation of an action such as stepping onto the moon, interpreting the meaning and significance of natural language utterances depends crucially on contextual factors and background knowledge” (Coulson 2001). Context is often considered to include the time, the location, the topic of discussion and other obvious factors that affect the topic being discussed or described in a document or database. Background knowledge, including exformation and subtext may also be included in context. I assume that systems that are broadly capable of delivering users actionable knowledge will be based on deep understanding of context.
I propose that the best way to scale the mountain of information, is to automate its conversion to knowledge. The approach I’ve described today to computerized understanding is very modular, and more granular than anything used widely today. At the core of this approach is Context. Examined closely, context itself is a multi-dimensional universe. In my next few posts, I will peel back the onion with you to find what’s inside.
| Click below to look in each Understanding Context section |
|---|
SHARE THIS ARTICLE




This post is very simple to read and appreciate without leaving any details out. Great work!
360digitmg data science institutes