



21 May What it Means to Be, and Why AI Needs to Know

 Joe Roushar – May 2018
Joe Roushar – May 2018
I relate, therefor I am
Interaction between humans is intricate, intimate and beautiful. Good conversations are like dances and can leave one feeling fulfilled and whole. I have long wanted to build a system that can verbally dance with you. Even longer, one to rapidly translate what you say with high accuracy into any number of other languages, enabling cross-cultural dances. After looking at this carefully over a long time, I decided that the system would first need to be able to deeply understand you before attempting to translate your words.
As I thought more about this, it occurred to me that the best way to test a system to see if it could deeply understand meaning would be to create a companionable digital assistant that participated with you in broad-ranging conversations, and proved that it could nimbly change topics just as a person can. Part of the complexity of this problem is that humans can change topics more than once, and pick up the thread of a prior topic right where they left off. In fact, if you look closely at the well-written documents, even well-written sentences, metaphor, allusion, idioms and subtext are frequent. These require large amounts of knowledge and context to fully understand.
Before I could possibly hope to build a system that can sustain an intelligent conversation with you, especially one that hopes to speak and listen across a broad range of topics, I felt a need to understand the foundations of both language and knowledge. Today, I would like to plumb the depths of BEING, and share with you some of my observations at the conjunction of Language and Knowledge where semantics meets ontology.
| Understanding Context Cross-Reference |
|---|
| Click on these Links to other posts and glossary/bibliography references |
|
|
|
| Prior Post | Next Post |
| More Agile than "Agile" | The Anatomy of Insight |
| Definitions | References |
| language understand sentence | Allemang Davies Wierzbicka |
| metaphor allusion idioms | Fensel Hirst Minsky |
| context taxonomy | Jackendoff Schema.org Goddard |
| representation concept | Distributed KR Universal Theory |
The question of “being” in Information Ontology Modeling
“To be or not to be?” may be a question of life and death, while “is it or isn’t it?” (another existential question) may just be the denouement of an argument. The philosophy of being is a wonderful morass, but it is not my intent in this post to argue with René Descartes about the sum of existence. Rather, I would like to revisit the importance of capturing the noosphere or cognosphere in a bucket of knowledge into which an artificially intelligent persona can dip to interpret what I say and respond with human-like dialog. “Classifying” knowledge or facts is an automated process through which computers organize such a bucket, and the approach is important to the questions of what it means to be, and why AI needs to know.
 I have heard people associate taxonomy, a powerful tool in describing the existence and classification of things, as if it is the basis of encoding all knowledge. In my journey of seeking to understand how to encode facts about the world to represent enough knowledge for complete, accurate language understanding, it became apparent to me that taxonomy is not enough. Taxonomy helps understand the nouns. But verbs don’t classify in the same way nouns do. Knowledge about meaning, semantic knowledge, is more complex than taxonomical classification, though they are often lumped together.
I have heard people associate taxonomy, a powerful tool in describing the existence and classification of things, as if it is the basis of encoding all knowledge. In my journey of seeking to understand how to encode facts about the world to represent enough knowledge for complete, accurate language understanding, it became apparent to me that taxonomy is not enough. Taxonomy helps understand the nouns. But verbs don’t classify in the same way nouns do. Knowledge about meaning, semantic knowledge, is more complex than taxonomical classification, though they are often lumped together.
When I was a student of linguistics, the science of semantics, seemed to be primarily focused on causality (identifying the agent, object and instrument of an action) and formal logic standards for expressing meaning. The agents, instruments and objects of actions are nouns. But the actions themselves, and their motivations and effects are not. The nouns can be classified in typical existential ways. The actions, processes and outcomes need logical models of knowledge representation and classification (see my post on Knowledge Representation). As you will see below, there is even more complexity than meets the ear.
Semantic Formalisms
Semantics may be simply defined as “the study of meaning in language understanding”. I just checked good ol’ Google, and found the following definition:
“The branch of linguistics and logic concerned with meaning. There are a number of branches and subbranches of semantics, including formal semantics, which studies the logical aspects of meaning, such as sense, reference, implication, and logical form, lexical semantics, which studies word meanings and word relations, and conceptual semantics, which studies the cognitive structure of meaning – the meaning of a word, phrase, sentence, or text” (no attribution).
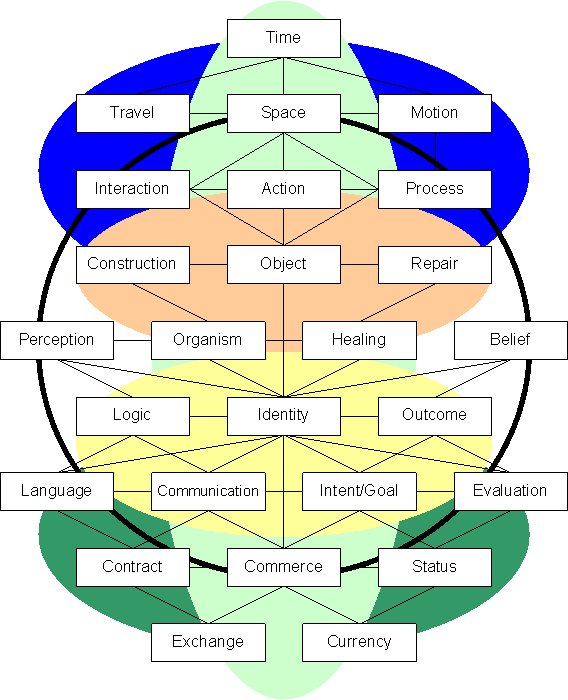 Semantic and logical formalisms have helped me tackle the vexing problem of getting computers to understand people, and I cannot overstate the value of ontologies in encoding these formulas for building, managing and using buckets of knowledge. As my research and experimentation have evolved, I have built models of meaning and context. I originally defined what is shown in the illustration at right as an encapsulation of universal contexts. As you will see below, this work has evolved, instead, into a model of semantic primitives that operate in any context. This formalization of things everyone already understands intuitively provides a mechanism for enabling computers to understand meaning digitally.
Semantic and logical formalisms have helped me tackle the vexing problem of getting computers to understand people, and I cannot overstate the value of ontologies in encoding these formulas for building, managing and using buckets of knowledge. As my research and experimentation have evolved, I have built models of meaning and context. I originally defined what is shown in the illustration at right as an encapsulation of universal contexts. As you will see below, this work has evolved, instead, into a model of semantic primitives that operate in any context. This formalization of things everyone already understands intuitively provides a mechanism for enabling computers to understand meaning digitally.
Semantic primes or primitives are root concepts expressed as familiar words that are understandable to speakers of any language, and which cannot be reduced to simpler concepts. They are represented by words or phrases that are learned through repeated exposure, experience and practice, but defy concrete definitions. Conversely, one or more semantic primes are necessary parts of any definitions of meaning or intent. Without logical propositions, a clear definition of meaning or intent is not possible.
And so I lay out a case and a framework for borrowing the concept of Ontology from the no-longer-listening philosophers to improve the ability of automated information systems to process knowledge. The meanings of “intelligence” and “life” are not to be covered here, even as they relate to Artificial intelligence and Artificial Life. It is possible that future systems may use ontologically encoded knowledge to simulate life in robots or other systems, but this post is primarily about existential inquiry into knowledge universals to support language interpretation.
Intent and Meaning
I use Google all the time, as do others in my circle – and your’s. Google uses semantics to help improve search results (SearchEngineWatch 2017). For more than 20 years, the use of semantics in search has been understood to be important (Fensel). A search engine is designed to try to get inside your head, based on the word(s) you type or speak, and find what you want (i.e. understand your intent). While search does not require full natural language understanding, using NLP techniques improves search results, thus winning willing adopters. These techniques have been fundamentally important in my personal quest.

When a person communicates using language, there is no guarantee the words will be understood as intended. In fact, it is just the opposite: because each person harbors a different understanding of the world, each person interprets words, phrases and sentences slightly differently. Tiny differences between what is spoken and what is understood by the hearers are usually acceptable – so it goes. An important part of understanding communication is doing the best one can to decipher intent. This is true whether the one attempting to understand is human or machine.
Intent is a pivotal component my semantic framework for language understanding. As a semantic universal (Wierzbicka), it is tied to a specific human and their motivation, in a specific instance described in words. Motivation and intent are interesting at multiple levels. At a linguistic level, intent is a construct of meaning that may (possibly) be derived from the text, the context and the subtext. At a human action level, intent is built of desire, and combined with knowledge and skill, can result in action (Covey). Although intent is very ephemeral, it may be at the root of most everything done by humans. Consequently, whenever action is involved in the language we are attempting to understand, the intent or motivation behind the action is a valuable component of comprehension.
 Fragments of History
Fragments of History

Folks have been trying to understand understanding since they first figured out what they didn’t know. Thousands of years ago, writings from Aristotle and other philosophers describe their musings, theories, thought experiments and conclusions. In the late 1600s to early 1700s, Gottfried Wilhelm Leibniz defined key constructs in formal logic. “A prominent theme of Leibniz’s writings is the systematic organization of knowledge, gathered from as many fields as possible, as a means to continued intellectual progress” (UCSD). Some of the principal properties he described include what we now call conjunction, disjunction, negation, identity, set inclusion, and the empty set. These are applicable to the cognitive aspects of both logic and language. Using predicate logic, Leibniz differentiated between modalities of “necessity”, “possibility” and “contingency”, all important to understanding the concepts expressed in human dialog.
“The nature of an individual substance or of a complete being is to have a notion so complete that it is sufficient to contain and to allow us to deduce from it all the predicates of the subject to which this notion is attributed. (Leibniz in Plato Stanford)”
In the 1800s Charles Sanders Peirce and Ferdinand de Saussure independently described a science now called Semiotics: the study of signs. Semiotics includes studies of every aspect of language and logic including semantic concepts of processes, indication, designation, likeness, analogy, allegory, metonymy, metaphor, symbolism, signification, and communication. Later in the 1800s, we have Martin Heidegger, and his concept of “Fundamental Ontology”. More recently, along with Wierzbicka and Goddard, we have John Sowa, Doug Lenat and Tim Berners-Lee who have used these formal ideas to create “information ontologies” and developed RDF and OWL. These are just a few of the salient fragments of history in this pursuit, but they have served as a basis for my work and the connection between semantics and ontology.
Modal Logic
As a computer geek, I have often found similarities between programming patterns useful for different domains. For example, in the domain of supply chain forecasting and execution, modeling techniques such as Monte Carlo Simulations are very useful. While in the domain of electronic commerce, distributed transations to a relational Online Transaction Processing (OLTP) database may be a good pattern. For processing large amounts of continuous input, such as logs , news feeds and social media, the data streaming pattern is good, while for periodic data exchanges between systems, bulk Extract/Transform/Load (ETL) is a common pattern. Logical patterns are slightly finer in granularity, and like programming patterns, the patterns are very distinct from one another.
Logic transcends domains in many cases, and a single pattern may be useful across many or most domains. In fact, “since the 1970s modal logic has developed equally intensive contacts with mathematics, computer science, linguistics, and economics; and this circle of contacts is still expanding. … Investigation of modalities has also become a study of fine-structure of expressive power, deduction, and computational complexity that sheds new light on classical logics, and interacts with them in creative ways” (IEP). The expressive power of the formalism is what appeals to me, because, for high-quality interpretation, the power of the formalism must align with the expressive power of the natural language it is attempting to reflect.
 Peirce’s five semantic primitives include: Existence, Co-reference, Relation, Conjunction and Negation. The five semantic primitives are available in every natural language and in every version of first-order logic. The illustration at right shows a set of logical operators that are used to formally annotate logical relations. These operators expand on Peirce’s five to recognize seven logical primitives associated with “Being”.
Peirce’s five semantic primitives include: Existence, Co-reference, Relation, Conjunction and Negation. The five semantic primitives are available in every natural language and in every version of first-order logic. The illustration at right shows a set of logical operators that are used to formally annotate logical relations. These operators expand on Peirce’s five to recognize seven logical primitives associated with “Being”.
| Logical Primitive | Informal Meaning | English Examples |
| Existence or Void | A thing exists or it does not | There is a particle in space |
| Co-reference or Distinction | Something is or not the same as something else | Water is H2O – Iodine is not Root Beer |
| Contextual Association | Something is or is not related to something | A dog sheds hair but a shed hairs no dog |
| Conjunction or Disjunction | (A and B) or (A or B) | Tippecanoe and Tyler or Van Buren |
| Affirmation or Negation | A or Not A | I am – you are not |
| Similarity or Difference | Something resembles something else – or not | Hail sounds like gunfire – but not like hell |
| Stasis or Change | Something is or is not the same as it was before | The change of guard drill is still the same |
| Probability or Possibility | Something may or may not happen in the future | You may have bought the winning ticket – but no ticket will ever buy me |
Of these, contextual; association is, to me, the most flexible and frightening. If the context of the association is encoded correctly and at a good level of granularity, the association can be both meaningful and helpful in language understanding. If either the context is unclear or at the wrong granularity, it will impair the system’s ability to interpret intent.
Wierzbicka’s Semantic Primitives include 54 items. The model I have developed to support language interpretation and translation distinguishes between framework universals, and experience actuals. Framework universals are primitives that can be identified without any effort to interpret the meaning or intent of input. Experience actuals are primitives that can only be derived from deductive processes applied to natural language input. The illustration below shows a framework of universal primitives and the top level experience primitives.
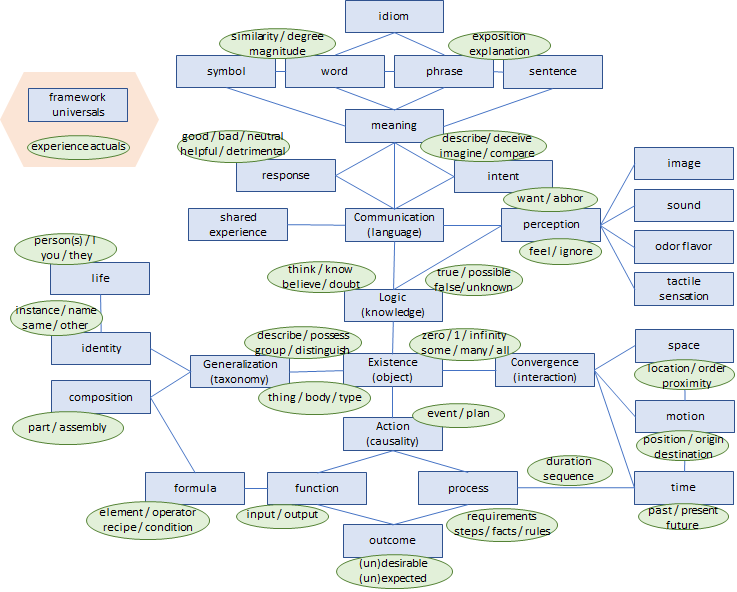
From a process perspective, we may distinguish between existential questions about interpretable input and the process of interpreting it. Specifically, we may, with very little effort, ask questions about the existence of input and its context to identify the presence of any framework universals in the input (including contextual information available in the “environment”). On the other hand, to deduce the values for the experience primitives, processes of parsing, classifying and disambiguating the input must be completed. In my software design, I use completely different types of processes for resolving univesals vs. actuals. Existing systems such as Siri, Cortana and Alexa parse and classify input, but disambiguation is still a weakness. For this, more expressive formalisms are needed.
 Experience is fundamentally more of an Ontic inquiry, than ontological, but the self-aware principles of ontology are necessary components of the ultimate information ontology solution that will successfully model enough knowledge to be able to interpret what people have to say about what is and what is happening. The ball, bat and all the players and officials exist outside the moment, as well as in it. The pitch, its speed, its accuracy (strike zone penetration), its spin and its appropriateness for the batter are all experiential or Ontic inquiries. An ontology may provide typical pitch attributes as associations, but only the recorded account of the pitch can deliver the details needed to describe and interpret (and possibly translate) the details in a way understandable to information consumers.
Experience is fundamentally more of an Ontic inquiry, than ontological, but the self-aware principles of ontology are necessary components of the ultimate information ontology solution that will successfully model enough knowledge to be able to interpret what people have to say about what is and what is happening. The ball, bat and all the players and officials exist outside the moment, as well as in it. The pitch, its speed, its accuracy (strike zone penetration), its spin and its appropriateness for the batter are all experiential or Ontic inquiries. An ontology may provide typical pitch attributes as associations, but only the recorded account of the pitch can deliver the details needed to describe and interpret (and possibly translate) the details in a way understandable to information consumers.
Ontology
Back to BEING — Ontology, as a science, is defined as “the branch of metaphysics that studies the nature< of existence or being as such” (Dictionary). The second, and looser definition is “metaphysics”. Information ontology is larger than the definition implies because it can encompass being, doing and evaluating. As such, Information Ontology combines meta-knowledge and meaning constructs with semiotics, in the form of knowledge representation theory. Systems that build and use information ontologies attempt to answer age-old questions including: What is knowledge, how is it captured, how is it conveyed and how is it understood? The framing of these answers includes the need to capture functions, intentions and motives along with the taxonomies of existing objects in an ontology in a way that they can be used to support automated heuristics and business processes.
 Information ontologies cannot limit themselves to TRUTH because falsehood, deception, analogy, metaphor and perception are often equally information-rich. This further demonstrates the need for logical modality tied to “concepts” in the knowledge base – yes – I see ontologies as repositories of both knowledge and meta-knowledge.
Information ontologies cannot limit themselves to TRUTH because falsehood, deception, analogy, metaphor and perception are often equally information-rich. This further demonstrates the need for logical modality tied to “concepts” in the knowledge base – yes – I see ontologies as repositories of both knowledge and meta-knowledge.
Passing Note: Much of my ontology and ontic work is empirical, but the results, when positive, can contribute to the science. Often, however, we are content to “limp along behind the sciences” and capture the facts the sciences discover or propose and disgorge rather than contribute a prescriptive philosophy of “being”. Please indulge my rebelliousness.
General Knowledge
There are many information ontologies built in OWL / RDF and freely available on the web. Linked Open Data on sites such as dbpedia.org contain a wealth of domain-specific ontologies. Heidegger asserts that all other ontologies must originate from Fundamental Ontology. Heidegger does not state whether this implies the existence of a core universal ontology, but such a core may be implied by many philosophers’ treatment of universally shared knowledge. As a matter of efficiency, I have built a core ontology to support my language understanding work. This core ontology describes things, actions, motives and value judgments that seem to me to be universally applicable. The core ontology describes objects, action and the elements of intent at all five levels I described in my High 5s post: domains, subdomains, entities, logical data elements and physical data elements. In addition, domain ontologies that describe successively narrower domains, such as Linked Open Data, may tie into the core ontology at the concept level.
 Anna Wierzbicka asserts that “semantic descriptions are worth only as much as the set of primitives on which they are based.” I agree, and further suggest that the task of using ontologies to support natural language understanding requires both a robust set of semantic primitives, and a core ontology that contains enough information about the subject matter of dialogues that are to be understood. This core ontology should span the breadth of all the accepted semantic primitives, and represent them in a useful way. Building such an ontology is a very tall order, but with the emergence of fully-automated machine learning and supervised learning, I think it is now possible.
Anna Wierzbicka asserts that “semantic descriptions are worth only as much as the set of primitives on which they are based.” I agree, and further suggest that the task of using ontologies to support natural language understanding requires both a robust set of semantic primitives, and a core ontology that contains enough information about the subject matter of dialogues that are to be understood. This core ontology should span the breadth of all the accepted semantic primitives, and represent them in a useful way. Building such an ontology is a very tall order, but with the emergence of fully-automated machine learning and supervised learning, I think it is now possible.
I learn by reading, so the very thing that I am trying to build may be able to build itself once basic capabilities are complete. Chicken and egg? Yes – the challenges are significant. But I feel we’re making progress and that is very encouraging.
 Drilling Further into Being and Information Ontology
Drilling Further into Being and Information Ontology

The question of “being” or existence has been addressed, over time, in many ways. While durability versus transience and the presence or absence of atoms are good ways to differentiate physical things from from things that have no substance, an information ontology may treat all things, abstract or concrete, using consistent formalisms. The universal theorist may describe a string theory in which everything that exists is a pattern of vibrations.
At the small and temporary end of the spectrum I may describe a simple fact of one person’s existence in which this person, Joe, gets indigestion when he eats onions. The specific patterns of vibrations that constitute Joe, the onion and the digestive process are all part of the broad question of being, though the vibrations that constitute indigestion are ephemeral. From a process perspective, I am equally interested in “understanding” Joe and onions and indigestion. I cannot accurately interpret and translate complex dialogues unless my processes and knowledge support all these types of knowledge.
Information ontologies can be used to represent aspects of “being” in models useful for knowledge storage, sharing, processing and reuse. As “Representation” is an important aspect of this effort, I have conveniently explicitly chosen “English” as the primary symbol system to represent knowledge in my framework for both the description and the mechanism for building my ontology. I could have chosen any human language or quasi-natural substitute, such as Esperanto, as long as the language is able to convey concepts like Joe and onions and indigestion from speakers to listeners or writers to readers. English happens to be my native tongue, so I beg your indulgence in this decision.
“Being” may be applied to the existence of any fact, whether it is a physical object the size of the known universe or an abstract concept as fleeting as a perceived doubt. Even fabricated facts may, unfortunately, have lives of their own. Everything has a self-contained “being” enclosed in a context, either physical or abstract. The context of the universe is that it is one of the physical things known to man and defined by the English word “universe”. A doubt is abstract, and its context is defined by the mind that conceived the doubt and/or the utterance or document that expressed it. Absent mechanisms for efficiently processing knowledge inside the minds of beings, we are confined to expressions of knowledge outside the mind, and I choose to further limit this work to knowledge expressed in spoken or written words.
 Chains of Reference
Chains of Reference
There is a potential circular argument I would prefer to avoid: the persistent recursiveness of the questions of “being” and “expression.” It may be akin to the observer effect in quantum physics. If abstract and ephemeral things such as the speed of a pitch and the level of digestive discomfort can be said to exist, then our object model can probably include verbal and written statements as well. The circularity comes from the existence of the newspaper article, that quotes the commentator, that described the pitch that now exists only in memory.
Such chains of reference are ubiquitous, often observing themselves and wrapping back upon the “existence” of the observation and its expression in words. The conceptual implications are difficult enough that I have no wish to delve into the philosophy. From an interpretation perspective, however, as long as you can describe the lineage of the concept and follow it through its verbal journey, understanding the intent of each utterance along the way can be straightforward. Following a chain, however, when words, sentences or entire side conversations take a different path, then come back to the topic are another story entirely. Many or most people are very good at pausing a thread, then picking it up where it left off. For machines to be able to do that, they need to have strong “episodic” memory capabilities tied to the semantic primitives mentioned above. By tracking different topics as threads, and remembering the episodes of discussing these threads, an automated dialog system will be able to switch topics as easily as humans. Making proper associations between threads, topics and episodes will also be essential for a fully-automated interpreter so that important shards or meaning are not forgotten or missed, even if they are drawn from apparently dissociated threads.
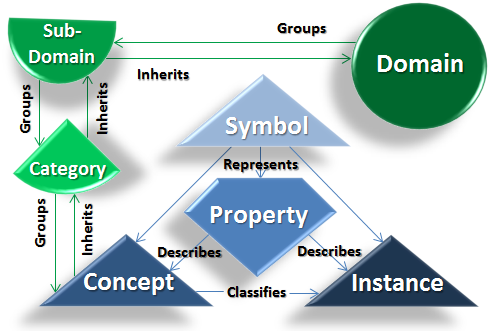 For simplicity, I concentrate on the contextual nature of being, understanding that regardless of the recursive fact of existence, any object that can be said to exist, does so in a context. The context surrounding any existing object, in my framework, is the most interesting fact governing the question of “being” for that object. This may not always be the case. But in the case of processing knowledge in an automated system, the context is the most faithful determinant of the nature of the being of any object represented in that system.
For simplicity, I concentrate on the contextual nature of being, understanding that regardless of the recursive fact of existence, any object that can be said to exist, does so in a context. The context surrounding any existing object, in my framework, is the most interesting fact governing the question of “being” for that object. This may not always be the case. But in the case of processing knowledge in an automated system, the context is the most faithful determinant of the nature of the being of any object represented in that system.
Shelf-Life of Knowledge
At a physical level, detecting the existence of and exploiting information is context-dependent. Many digital systems use tiny variations in electrical potentials, often measured in millivolts, to differentiate between the ones and the zeros that hold all the information in a system. The ones and zeros do not exist, but are represented by electrical concentrations traveling through wires to devices with registers, and stored on media in which physical areas of the medium are expected to contain information that is electronically readable. Without a device that “knows” how to “read” the content of the storage medium, and where on the medium to “look” for it, the content is not accessible and effectively ceases to meaningfully exist for that context.
 There are vast quantities of 5 1/4 inch “floppy disks” that once could be said to contain vast quantities of useful information. They now require so much effort to find a capable “reader” that the information they hold can be said to no longer exist for all practical purposes. Similarly, writings in “dead” languages contained quantities of useful knowledge to human readers. Unless translated, these texts are empty, useless, and virtually non-existent knowledge for most living readers. Conversations that are not recorded, even if the topics and opinions were of huge value, soon fade into non-existence.
There are vast quantities of 5 1/4 inch “floppy disks” that once could be said to contain vast quantities of useful information. They now require so much effort to find a capable “reader” that the information they hold can be said to no longer exist for all practical purposes. Similarly, writings in “dead” languages contained quantities of useful knowledge to human readers. Unless translated, these texts are empty, useless, and virtually non-existent knowledge for most living readers. Conversations that are not recorded, even if the topics and opinions were of huge value, soon fade into non-existence.
To extend the shelf-life of information, I think a few things are needed:
- Store it in a format that can survive over long times: Not papyrus nor paper, not floppy disks nor cassette tapes
- Annotate it with metadata that describes its intent, authorship, sensitivity, reliability and context
- Make copies and store them in safe places
The metadata is a huge gap in modern enterprise information management with few standards (though Apache Atlas is emerging), and few effective implementations that can be managed and bring broad and lasting business value.
The connection between information, metadata, storage and semantic information ontologies is usability. Thorough, accurate information ontologies make information much easier to understand and use. This further enables consumers to extract maximum value from the information with manageable levels of effort. Companies spend enormous sums of money to store and manage information. And even though Information Technology (IT) is considered very mature by most, it is the automated systems with narrow capabilities that are most mature. Information life-cycle management is still relatively immature, and will remain so until organizations implement “meaning models” (ontologies) and metadata to tie information assets to the models. For effective artificial intelligence systems, this is particularly necessary.
Meaning in the Model
Heidegger, in “Being and Time” invokes Kant – “The covert judgments of common reason…” to suggest that we introspective philosophers focus querulously on that which is self-evident, and interminably question our questions. I am often guilty of this, but I’m hoping that this post brings out and clarifies defensible ideas. I will come forward in future posts with evidence to support some of today’s assertions and pull this out of the realm of vague inquiry, and into the light of observable outcomes. In many posts in this blog, and in its structure (see table of context), I have assumed that the solution to the problem with which I opened this post must be neuromorphic, or at least functionally similar to cognition. I have posited that some of the same processes needed to build, manage and use a digital bucket of knowledge correspond to cognitive processes as shown in the illustration below and articulated in my section on cognition.
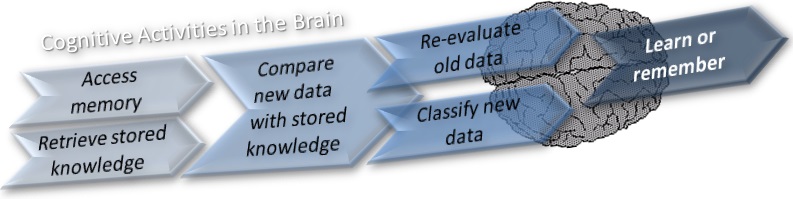 The ideas about existence and meaning presented in this post neither assume that knowledge requires empirical evidence, nor rational processing, but that there exists a body of knowledge that can be represented in one or more ontologies. I further assert that a robust model of semantic primitives, intelligently represented in the ontologies, can lead to better understanding of information that is encoded as natural human language. The processes that exploit this knowledge should probably mirror human thought in fuzzy ways. Using a distributed or bottom-up approach to defining discreet elements of knowledge, we can ignore the philosophical questions temporarily, and focus on determining whether discreet statements of fact in a knowledge network constructed as an information ontology can be used reliably by seekers of information (personas), and systems with their own personas that crave social dialog.
The ideas about existence and meaning presented in this post neither assume that knowledge requires empirical evidence, nor rational processing, but that there exists a body of knowledge that can be represented in one or more ontologies. I further assert that a robust model of semantic primitives, intelligently represented in the ontologies, can lead to better understanding of information that is encoded as natural human language. The processes that exploit this knowledge should probably mirror human thought in fuzzy ways. Using a distributed or bottom-up approach to defining discreet elements of knowledge, we can ignore the philosophical questions temporarily, and focus on determining whether discreet statements of fact in a knowledge network constructed as an information ontology can be used reliably by seekers of information (personas), and systems with their own personas that crave social dialog.
Why AI needs to know
We’ve seen amazing advances in personal digital assistants from the early Palm Pilots to today’s smartphones and pad devices. Humans are social beings and computers are not inherently so. But the technology transformations of mobile and social computing are breaking down the old paradigms. The system that can verbally spar with you is not far away, but I predict that it won’t be able to credibly riff on intermingled topics until its ontology matures in the ways I have articulated in this post. Semantic understanding is not trivial, and the needed advancements should be focused on knowledge and process models that are not based on a chauvenistic “garbage in – garbage out” philosophy, but treat your words as valid and worthy of considered response. The science behind building the knowledge model must include semiotics as well as linguistics, philosophy, anthropology and the full array of cybernetic thinking.
Organizations that have attempted to implement advanced AI capabilities have learned that models of “intent” are critical to successful implementations that achieve measurable business value. Machine Learning algorithms as well as decision support and expert systems need broader perspectives on “meaning” and “intent” to deliver optimum business value. These advancements are just over the horizon. Stay tuned.
Click below to look in each Understanding Context section
SHARE THIS ARTICLE



