



10 Jun Knowledge is the New Foundation for Success
 Joe Roushar – June 2020
Joe Roushar – June 2020
Retooling for The Beginning of a New Age

This year, 2020 will be the turning point in AI adoption because successful implementations will be available to small and large organizations without breaking the bank. Success will be measured in specific business value achieved. Affordability will dramatically improve because of AI integrations that convert raw data, documents and structured information into actionable insights. Computers will finally be able to truly understand meaning bringing a rapid and disruptive transition from information to knowledge marking the end of an age.
The information age is wearing down, and before long it will give way to the Age of Knowledge. The AoK will be characterized by further acceleration in innovation, and we hope, democratization of online knowledge access. But access to knowledge will unequally benefit those who know the right questions to ask, whom to ask and what to do with the answers. The “whom” will become a smarter virtual agent. Advances will happen sooner in some organizations with the introduction of natural language understanding (NLU) based Artificial Intelligence (AI), Machine Learning (ML) and cognitive computing capabilities. And like the start of rain on a lake, the ripples will spread out from a few, then more, than countless points. No matter the size of your business, large or small, and no matter what industry, implementing the right mix of fundamental capabilities can profoundly simplify introduction of AI, ML and cognitive computing to improve operations, margins and competitiveness. Knowledge is the foundation of business success, and intelligent AI lifecycle automation is the key to minimizing implementation turbulence.
AI and ML are no longer futuristic ideas: they are here – and differentiating organizations that successfully build them into their digital strategies. What is the most important component of your digital strategy? Is it web and e-Commerce? Is it customer engagement? Is it transformation or disruption? To achieve the most positive disruptive impact, harnessing your information assets must be a key pillar of your competitive strategy, and AI can help you maximize value. Information is at the center, it’s increasing at an alarming rate, and smarter management is required to make it more accessible and useful to decision-makers.
Understanding Context Cross-Reference: Links to other posts and glossary/bibliography references
|
|
|
It all comes down to a decision
All outcomes hang on decisions. How can human-like reasoning and learning capabilities in information systems help improve competitiveness, and which capabilities are the most important? The specific details differ for each organization. But the broad outlines are the same. Automated data processing reduces human effort and time while improving information retention and quality. The trend over time has been for systems and processes to assume more complex tasks, and draw closer to delivering actionable intelligence. Actionable intelligence promises to improve and expedite business decisions. Actionable intelligence also crosses an important threshold, pushing digital information to the level of knowledge: hence the dawn of the “Age of Knowledge“. The best way to scale the mountain of information is to automate its conversion to knowledge, reducing your reliance on brittle legacy systems. I will describe an approach to computerized understanding that is modular making it easy to architect and integrate, and more granular than anything used widely today. At the core of this approach is a meaning model that puts everything in context.

Brittle Systems Delay Good Decisions
Before proposing a strategic transformation, we should establish where there is room for improvement. While Wikiwand points to a systems age as a cause of brittleness, it also arises from size and complexity. Here is a list of technology challenges that can impair an organization’s ability to empower its workers with the knowledge they need to make solid decisions:
- The system works great but it won’t scale
- The system scales but it’s too hard to adapt
- The system is so complex that modifications can compromise it in unknown ways
- The system requires unique or legacy skill sets, making adaptation more costly and risky
- Meaningful information requires too many joins so complex queries fail
- Building multi-dimensional analytics blows the budget without commensurate results
- There are no good metrics or KPIs that tell us the “why” or “how” of trends
- Developing scenarios and evaluating outcomes seems like a black art
- Building and modifying systems takes too long placing us behind competition
- There is never enough money to build the ideal system
Sound familiar? If any of these challenges resonate with you, it may be time to take a look at a new approach where monolithic ERP, CRM and other legacy systems no longer hold you back. We’re not talking about replacing them – that’s too costly. We’re talking about augmenting your systems and the broader IT portfolio with more intelligent capabilities. Augmenting them with good data tools is critical and AI is an obvious solution. This is evidenced in recent acquisitions where top data companies are integrating AI capabilities: Boomi, data movement and prep software, and Qlik, data association and visualization software among many others.
Capabilities and Processes to Outcomes and Performance
Every important project and activity drives an intended outcome. Mapping the processes in a taxonomy that includes value chains and capabilities along the value chain serves to bring the outcomes into clearer focus. To use AI to improve outcomes, some systems and even their underlying code must reflect an AI-enabled strategy. Not all systems are ready for AI. This is especially true of legacy systems, and while their brittleness may not permit tight AI integration, loose integration through intelligent process automation (IPA) is often enough to open the door to AI that is often blocked by legacy systems. IT transformations begin by understanding capabilities needed to run the business competitively, and redefining automation strategies to improve outcomes. Modeling capabilities to outcomes in process value chains requires coordinating people, process, technology and content.
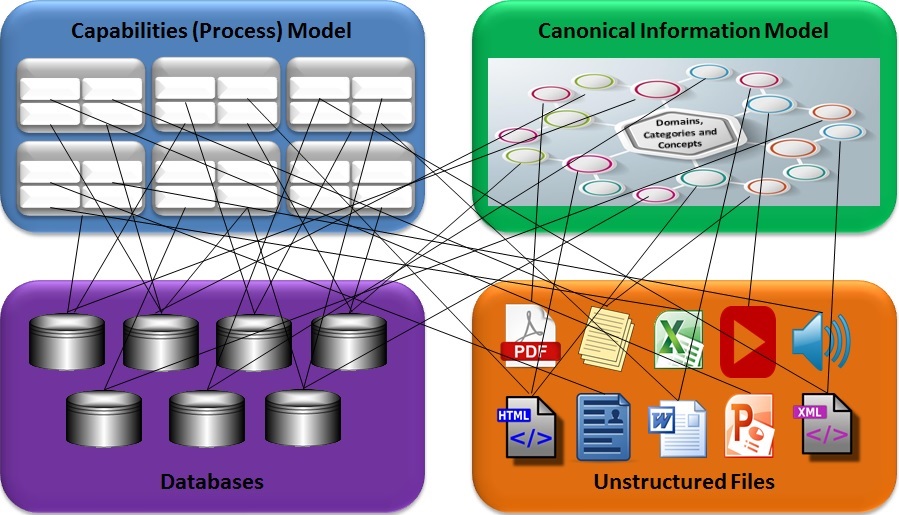
A useful process model can be illustrated as a taxonomy based on a multi-tiered organization of capabilities, functions and processes. Level one capabilities are broad like “finance” and “manufacturing”, and the model shows which sub-capabilities form value chains and sub-domains of knowledge in the organization for each level one capability. Level two is sub-domains or categories and level three describes discrete concepts. At every level there is likely to be overlap where concepts fit into more than one category and categorys cross domains. Efficient models typically go no more than three or four levels deep. At the bottom level of capabilities, processes can be diagrammed as process flows. These are represented by process flows in the diagram below. It is common, though often inaccurate, to associate capabilities with large, expensive systems at the top level. Capabilities often cross the boundaries of large systems, and the broader capabilities and value chains may require flow diagrams, stories and even pseudocode that transcend system boundaries to describe day-to-day operational activities or requirements.
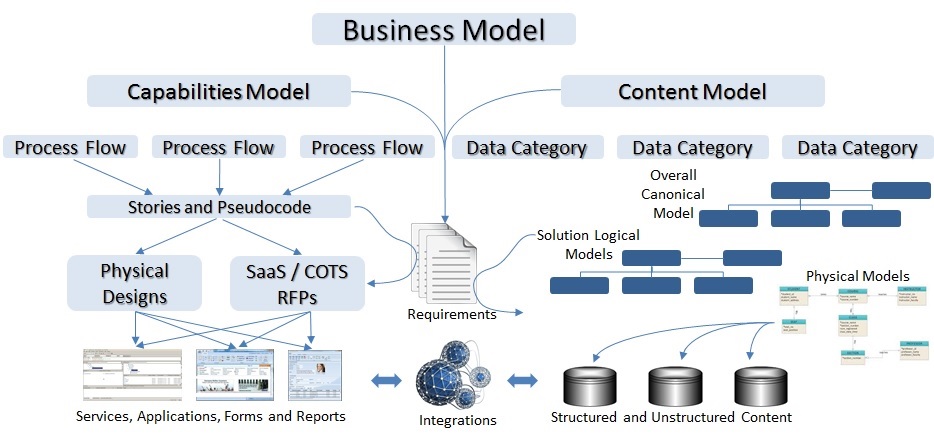 Rather than succumbing to the temptation to associate major systems with competitive advantage, a closer look at the broader portfolio of apps, including mobile and productivity apps, services, reports and data entry forms is helpful. A bottom-up view of an organization’s systems portfolio is facilitated by mapping applications and services to lower level (often level 3) capabilities in the taxonomy. In so doing, opportunities for AI can be associated with specific areas of weakness in the organization’s processes, or opportunities to outperform the competition. Knowledge and processes are co-dependent and cannot be divorced. A holistic granular view of processes is a necessary foundation for retooling to support AI and ML. Here again, Intelligent Process Automation is a powerful option.
Rather than succumbing to the temptation to associate major systems with competitive advantage, a closer look at the broader portfolio of apps, including mobile and productivity apps, services, reports and data entry forms is helpful. A bottom-up view of an organization’s systems portfolio is facilitated by mapping applications and services to lower level (often level 3) capabilities in the taxonomy. In so doing, opportunities for AI can be associated with specific areas of weakness in the organization’s processes, or opportunities to outperform the competition. Knowledge and processes are co-dependent and cannot be divorced. A holistic granular view of processes is a necessary foundation for retooling to support AI and ML. Here again, Intelligent Process Automation is a powerful option.
Model Content Semantically
 The business model diagram above shows processes on the left and content on the right. Just as a holistic process view is a great starting point for implementing more intelligent processes, a model with metadata of all information assets, structured and unstructured, in a coherent semantic catalog forms the second leg of the table. A holistic approach is best because, in addition to brittleness, many systems in an organization can be siloed or disjointed. Some of the worst and most common causes of silos are the boundaries that separate data in structured databases from unstructured documents that may provide important background, explanations and insight into the “whys” and “hows” behind changes in the performance metrics. Transaction and other data in databases almost never speaks for itself, and requires human analysts to interpret the business meaning. Business Intelligence tools and visualizations can help expose business meaning, but usually show only correlations, and even these analytics tend to be overly siloed.
The business model diagram above shows processes on the left and content on the right. Just as a holistic process view is a great starting point for implementing more intelligent processes, a model with metadata of all information assets, structured and unstructured, in a coherent semantic catalog forms the second leg of the table. A holistic approach is best because, in addition to brittleness, many systems in an organization can be siloed or disjointed. Some of the worst and most common causes of silos are the boundaries that separate data in structured databases from unstructured documents that may provide important background, explanations and insight into the “whys” and “hows” behind changes in the performance metrics. Transaction and other data in databases almost never speaks for itself, and requires human analysts to interpret the business meaning. Business Intelligence tools and visualizations can help expose business meaning, but usually show only correlations, and even these analytics tend to be overly siloed.
Information gaps and duplications between the silos inevitably limit the effectiveness and accuracy of AI and ML processes without a single “converged” source of metadata that spans the entire portfolio of databases, documents and rich media files. The asset catalog is canonical metadata that can fill the gaps when each element in the model is:
- A clear representation of a discrete semantic concept
- Tied to records of all information assets in the organization containing that concept
- Tied to all records of information assets in the organization directly associated with that concept
- Tagged with sensitivity information that supports compliant access control
Direct associations, especially causal associations open the door to AI and ML and qualitative analytics. The illustration below shows a tiny piece of an enterprise semantic model with causal links. The fact that a shipping company is sometimes unable to keep a time schedule because of floods, hurricanes or blizzards affects promised delivery dates. Shortages of equipment such as barges or rail cars (not uncommon) may delay grain delivery and result in spoilage. Accurate calculation of the exact day printed ads for a national campaign arrive in every mailbox may be extremely complex, but may be essential to the ultimate success of the marketing effort. Today, thousands of workers in thousands of companies correlate this information manually. They are often very good at this and effective in formulating assumptions and coordinating good decisions. But, truth be told, there is often guess-work involved – and errors due to insufficient data.
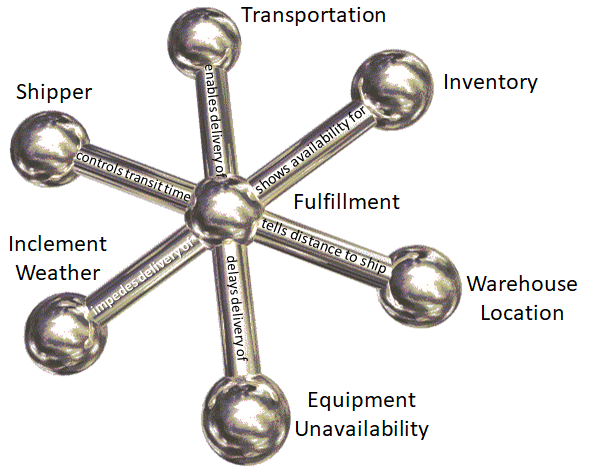 The availability of data has increased exponentially while our ability to exploit it has only incrementally increased. An important key to a quantum leap in our ability to exploit information is automating its discovery, semantic classification and cataloging. Not only is the secure semantic metadata required for maximally effective AI and ML, but AI and ML may be necessary to build and manage the model. Intelligent discovery bots are needed to crawl, classify and catalog the assets because of the large quantity and variety of information assets in many organizations: usually too much for manual data entry and management.
The availability of data has increased exponentially while our ability to exploit it has only incrementally increased. An important key to a quantum leap in our ability to exploit information is automating its discovery, semantic classification and cataloging. Not only is the secure semantic metadata required for maximally effective AI and ML, but AI and ML may be necessary to build and manage the model. Intelligent discovery bots are needed to crawl, classify and catalog the assets because of the large quantity and variety of information assets in many organizations: usually too much for manual data entry and management.
There is a catch to process and content modeling: you have to keep them up to date. Because both can be significant in breadth, and can be subject to change, it is best to rerun discovery processes periodically and distribute the management responsibility for managing the models among the stakeholders who are most familiar with each functional area of the company. This distribution of metadata management responsibility is often done as part of a data governance board or an architecture governance board, and each stakeholder on the board may be named as a “steward” with specific management scope tied to their area of responsibility in the business. D.R. Shanks has done a large amount of work in both concept learning (content) and causality (process) well worth the time to pursue.
Explicit Associations: The Glue
Once we have modeled the processes and content that are needed to operate the business and compete, we can formally define the associations between different processes, between concepts and categories, and between the processes and the related concepts. This bottom-up process of placing the processes and concepts in context is the foundation of the semantic enterprise. The big picture of how everything is interconnected may be difficult to understand and even a bit chaotic when viewed as a whole, but labeling links with meaningful associations between nodes creates a context in which the relationships between the processes and content are explicit and consumable. Furthermore, using automated discovery to create and maintain these linkages in a loosely coupled single ontology makes the work of creating the catalog possible, and maintaining it manageable.

Vendors and systems architectures have long envisioned and prototyped semantic capabilities, and semantic layer architectures as part of more agile enterprises and forward-looking data stewardship. There are tools, including master data management systems, that attempt to achieve many of these benefits. But they require so much manual care and feeding, and contain insufficient semantic context to reduce the amount of human analysis required to implement effective AI and ML. This means they seldom deliver enough actionable knowledge to reduce the amount of human analysis needed to make a difficult decision confidently. The gap can be filled using holistic converged models as described above, with secure semantic metadata applied at the document and database level, and concept learning bots to build and maintain the complex associations that govern meaning and business value.
Implement Machine Learning
 Automated learning algorithms and bots can serve many different functions that improve an organization’s ability to exploit their information assets. Common applications include pattern learning algorithms that analyze a large set of data to identify hidden patterns such as unexpected associations between items purchased in an online store. User feedback gathered after e-commerce, search or query activities can be fed into ML to improve the accuracy and usefulness of advanced search. Converged knowledge discovery and machine learning capabilities can help workers build and maintain canonical semantic information models that cover all information assets. The models feed reliable search and query pre-processors to form a new, more intelligent part of an existing portfolio of systems. Introduction of any of these capabilities can improve user experiences, increase adoption, and show technology and business leaders how intelligent systems can improve operational efficiency and decision quality.
Automated learning algorithms and bots can serve many different functions that improve an organization’s ability to exploit their information assets. Common applications include pattern learning algorithms that analyze a large set of data to identify hidden patterns such as unexpected associations between items purchased in an online store. User feedback gathered after e-commerce, search or query activities can be fed into ML to improve the accuracy and usefulness of advanced search. Converged knowledge discovery and machine learning capabilities can help workers build and maintain canonical semantic information models that cover all information assets. The models feed reliable search and query pre-processors to form a new, more intelligent part of an existing portfolio of systems. Introduction of any of these capabilities can improve user experiences, increase adoption, and show technology and business leaders how intelligent systems can improve operational efficiency and decision quality.
Many intelligent functions such as cognitive search, self-service analytics and dialog-based workflows go beyond user-friendly to empower knowledge workers more than current systems can. User-focused ML can actually give business users more control over what their systems do for them, without costly, time consuming IT implementation cycles. Cognitive systems based on enterprise knowledge and process models that span the organization rely on exploitable information, and the surest way to prepare enterprise structured and unstructured information sources for ML algorithms is with an inclusive semantic canonical model. The model provides a foundation of meaning for sustainable cognitive processes throughout the organization.
What is Needed to Build a Solid Foundation?
An important key to implementing ML is modeling the full vertical (within information silos) and horizontal (across internal boundaries) ranges of enterprise information and technologies. Doing so requires both automated discovery that can infer the meaning in information and systems, and architects or analysts with the skills and expertise needed to curate and capture the multiple levels of granularity needed to bring cognitive systems to life. But the process cannot follow the traditional patterns of thinking that originally created the silos. Silo thinking is characterized by the false assumption that a linear process is needed to deliver the best outcome. True – there is likely to be a relatively straight “happy path” to the outcome. But then reality steps in, and exceptions increase until the standard process applies to only a fraction of the actual cases. To adapt to the rich variety of actual experience, multiple systems, processes and data are needed: a semantically interconnected enterprise is needed.
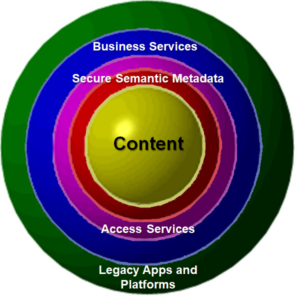
To support both the happy path processes and the adaptations needed to handle all possible exceptions we need smarter, more connected apps. Legacy apps and platforms need not be discarded in the effort to adapt to this brave new world. Business and IT leaders simply need to understand that information is where the value resides. Information assets in databases, documents, videos and web and social media sources can be collectively called “content”. Content must be understood to be a primary source for extracting business value. To make that possible AI needs to learn your IT ecosystem, connect your apps, and mine the web to deliver actionable knowledge. This is where semantic services are needed to profile your data, and catalog it as a first step to interconnect business systems, web, social, mobile and IoT into a golden egg.
The golden egg metaphor is a good way to look at content assets. But as soon as we combine content and processes, a better metaphor may be fabric. In the section of this blog on the human neural network I borrowed this metaphor in its poetic reference to the Enchanted Loom. Later in the section on Apps and Processes I showed the importance of holistic information models and building intelligence into microservices. Whether we think of it as a golden egg or an elegantly interwoven fabric, the intent is the same: build business services that optimize knowledge workers’ ability to find and exploit the information assets that will lead to the best decisions. This is the path to AI delivering better outcomes and more competitive strength.
Our approach based on semantic metadata built using advanced natural language understanding is the fastest route to smarter apps, deeper insights and more effective digital transformation.
It’s all in the Repository
Repositories help data stewards, modelers, administrators and engineers define and use the metadata that describes the meaning, value and sensitivity all structured and unstructured information objects. To simplify building and managing data dictionaries, AI bots should scan data sources and automatically build and periodically update the catalog. While data dictionaries are often vendor or technology specific, global heterogeneous data dictionaries may support multiple database types and unstructured data as well. Semantic associations between data tables and columns in the catalog will dramatically increase its usefulness and empower users through the ability to perform meaning-based search and query, which is much more flexible, and often more accurate than “keyword-based”. Intent models describing domains, sub-domains, concepts and associations are based on robust semantic associations. The intent models are the most critical for successful AI implementations.
Obstacles to AI
 Some of the barriers to successful AI and ML implementations are getting worse:
Some of the barriers to successful AI and ML implementations are getting worse:
- Too much data and too many apps: duplicate data and systems lead to unclear information
- Every new IT project reinvents the information model worsening the disjointedness
- Users and developers struggle to build and get good information: legacy IT approaches compound the problem
- Selecting narrow applications for AI and ML is good, but often difficult without broader information
- Developers don’t fully understand or have the skills to implement AI or ML
- Business stakeholders may have difficulty articulating or envisioning the outcomes AI can improve
A September, 2019 Gartner report suggests that the skills gap is the number one barrier “The first barrier is skills. Business and IT leaders acknowledge that AI will change the skills needed to accomplish AI jobs.” They go on to say that fear of the unknown is the second barrier. The third barrier is the vast amount of information needed. Finding a starting point and vendor strategy were other barriers their survey respondents reported, but data is critical: “Successful AI initiatives depend on a large volume of data” and “without sufficient data — or if the situation encountered does not match past data — AI falters” (Gartner 2019). Our assessment is that the data needed for AI and ML to improve business outcomes is often available, but people don’t know where to find it or how to best assemble it to support advanced initiatives.
Architecting for Intelligence
Here are some guiding principles for defining macro (Applications and major data stores) and micro (services and individual data assets) architectures needed to more efficiently introduce AI and ML into the technology portfolio:
- The information catalog needs to learn about everything
- Learn Business domains (Finance, HR, Legal, Ops, IT, Sales, Marketing + Industry spec…)
- Learn Geographies (by city, state country, distance…)
- Learn KPIs (What businesses care about…)
- Learn major IT systems (Generalizable to many…)
- Exploration may be self-guided and system-guided
- Provide support for citizen developers in BI and upstream processes
- Consider implementation of an enterprise knowledge bus or knowledge gateways to manage knowledge flow
AI and ML can be used to augment upstream Transactional Services that write, manipulate and move information. This will often be easiest with Intelligent Process Automation tools. AI and ML can also augment downstream Delivery Services that report, analyze and visualize information. This is the domain of advanced analytics. Enterprise architectures with multiple tiers have been around for decades, and the number and specialization of tiers has steadily increased. This evolutionary complexification is not a bad thing as long as the user is always sheltered from the complexity. Embedding all the complexity inside mega apps is a bad thing, often increasing dependence on single vendors and decreasing opportunities for strategic transformation and intelligent capabilities. I will dedicate a future post to elucidating these architectural elements, but this architecture provides important segregation and isolation for specialized intelligent functionality.
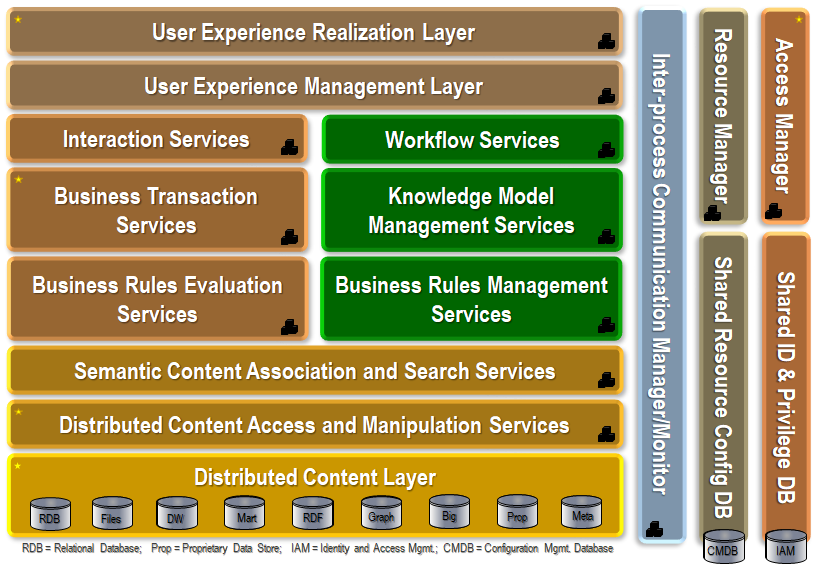
Knowledge model management services in this architecture include discovery and curation. The number and sizes of information assets in the organization, and the maturity of the inference processes in each domain of knowledge will determine the number of people needed to curate and govern information. Team- and crowd-sourced curation are often good options and tools to manage this are available from companies such as Hivemind. Key processes in the architecture can be defined at a level more basic than the major applications that sit astride the ERP, CRM, HRM, LIM legacy applications. These basic processes are the ones that can most benefit from artificial intelligence:
| – Find | Get or wrangle the information needed to support a business activity or decision |
| – Associate | Apply advanced semantic techniques to show how each bit of information contributes to a decision |
| – Infer | Apply rules and associations to discover and answer what – when – where – who – why – how |
| – Report | Create quantitative (what – when – where – who) and qualitative (why – how) visualizations and dashboards |
| – Explain | Explanation utilities use the Meta-Schema to help users understand the output and describe its logic |
Given the need to exploit information assets by finding, associating, inferring, reporting and explaining actionable information, where does the intelligent process automation that enables AI belong? Our position is that the place for the catalog is in the Secure Semantic Descriptors layer, the APIs and data movers belong in the Content Access Services layer, and the intelligent process automation belongs in the Business Services layer. These building blocks of AI bind together the warps and woofs, becoming the information and process fabric of the intelligent enterprise.

Assessing the Value
 With the long history of mixed to poor results in AI implementations, why even start? We see three distinct views of the benefits of disruptive changes in software architecture and engineering needed to support successful AI implementations:
With the long history of mixed to poor results in AI implementations, why even start? We see three distinct views of the benefits of disruptive changes in software architecture and engineering needed to support successful AI implementations:
- Business View (what disruptive AI brings businesses)
- Competitive Differentiation
- Adaptability
- Speed to Insight
- IT View (what disruptive AI architecture and engineering brings IT)
- Cost and effort of implementing new capabilities
- Cost and effort of supporting operational systems
- Pain-quotient of governed and ungoverned change
- Transformational View (Change is inevitable – sustainable disruption characterizes good change)
- Is the direction of change positive, and how do you know?
- Is the velocity of change sustainable (not to fast or slow)?
- Is the turbulence created by change acceptable, or does it increase firefighting beyond acceptable levels?

There are vendors that offer each of these capabilities. As an example, IBM will sell you IBM BPM, Datastage, and a whole suite of Watson modules. The challenge is that they are separate tools with separate frameworks and models that are not pre-integrated. My objective is to offer the whole suite in a single, integrated Intelligent Process Automation suite.
In January, 2020, @shoecatladder said “Programmers live with the curse of describing an interaction which is absolutely precisely defined and deterministic, using human language that is ultimately metaphoric, self-referential and subjective.” Might I add: “with data that is unreliable and often incomplete or off point.” The gap between subjective human language and declarative logical program code and data will exist into the foreseeable future. But the quality of tools we use to bridge that gap is improving every day ultimately making computers more helpful and data-based decisions more reliable.
| Click below to look in each Understanding Context section |
|---|
SHARE THIS ARTICLE



